


Volume 11 Number 4
Unraveling reported dreams with text analytics
Abstract
We investigate what distinguishes reported dreams from other personal narratives. The continuity hypothesis, stemming from psychological dream analysis work, states that most dreams refer to a person’s daily life and personal concerns, similar to other personal narratives such as diary entries. Differences between the two texts may reveal the linguistic markers of dream text, which could be the basis for new dream analysis work and for the automatic detection of dream descriptions. We used three text analytics methods: text classification, topic modeling, and text coherence analysis, and applied these methods to a balanced set of texts representing dreams, diary entries, and other personal stories. We observed that dream texts could be distinguished from other personal narratives nearly perfectly, mostly based on the presence of uncertainty markers and descriptions of scenes. Important markers for non-dream narratives are specific time expressions. Dream texts also exhibit a lower discourse coherence than other personal narratives.
1. Introduction
2. Related work
3. Data
3.1. DreamBank
3.2. Personal Stories
4. Experiments
4.1. Text Classification Experiments
| Approach | Prec | Recall | F1 | TPR | FPR | AUC | # correct |
| SVM | 0.97 | 0.97 | 0.97 | 0.97 | 0.03 | 0.97 | 38,225 |
| Balanced Winnow | 0.97 | 0.97 | 0.97 | 0.97 | 0.03 | 0.97 | 38,334 |
| Naive Bayes | 0.97 | 0.97 | 0.97 | 0.97 | 0.03 | 0.97 | 38,229 |
- Dream reports are characterized by words that convey uncertainty and retrieval from memory: somebody (rank 3), remember (rank 5), somewhere (rank 12) and recall (rank 17);
- Another category of features that have a high rank in dream reports are references to a space or situation: setting (rank 1), riding (rank 8), building (rank 16), swimming (rank 23), table (rank 25) and room (rank 30);
- In contrast to dream reports, personal stories contain indications of specific points in time: 2014 (rank 4), today (rank 9), tonight (rank 19), yesterday (rank 21), day (rank 23) and months (rank 28);
- Personal stories are also distinguished by conversational utterances, such as ‘:)’ (rank 2), please (rank 17), ‘?’ (rank 20) and thanks (rank 27).
4.2. Topic modeling
4.2.1. LDA on the DreamBank
| 44 | money pay get give buy bank bill machine change |
| 37 | bathroom water toilet shower use clean bath floor sink |
| 25 | class school teacher students high test room classroom college |
| 42 | room door house see window open apartment go living |
| 5 | road hill tree see walking snow mountain trees people |
| 28 | love feel kiss make happy want man other hug |
| 35 | say says do see go man woman comes get |
| 48 | said did went came got told started saw looked asked |
| Male | |
| 0 | gun fire men shot shoot man police shooting war deer |
| 5 | road hill tree see walking snow mountain trees people side |
| 11 | dream remember seemed do time being other same feeling something |
| 15 | car driving drive road street get truck going front side |
| 17 | bed room sleep sex sleeping lying bedroom floor naked lay |
| 29 | game playing ball play team basketball football field baseball cards |
| 33 | plane fly flying sky air see airplane land people ground |
| 34 | building floor stairs get go elevator people steps see walking |
| Female | |
| 12 | wedding married john wife getting ring husband george bonita ceremony |
| 14 | things room put stuff box small old boxes take find |
| 21 | wearing white dress black blue dressed clothes red shirt shoes |
| 23 | house mother father home brother family old sister parents children |
| 26 | get go do going trying take want find time know |
| 39 | girl friend dream girls friends remember went dreamed did school |
| 40 | man woman men young other women boy old older small |
4.2.2. LDA on dreams versus personal stories
| Dreams | |
| 23 | room house door see go floor open stairs window apartment |
| 40 | saw came said went looked got ran walked horse did |
| 1 | water see boat pool river swimming lake beach go people |
| 28 | dream remember seemed girl man boy came saw dreamed being |
| 13 | see go says say man woman get look comes walk |
| Non-Dreams | |
| 26 | do time get things think going know something make other |
| 45 | fucking shit fuck do get im know day got dont |
| 30 | feel do life help depression anxiety get know feeling want |
| 22 | relationship do want feel other months boyfriend tl girlfriend friends |
| 24 | day last today work get going week night got time |
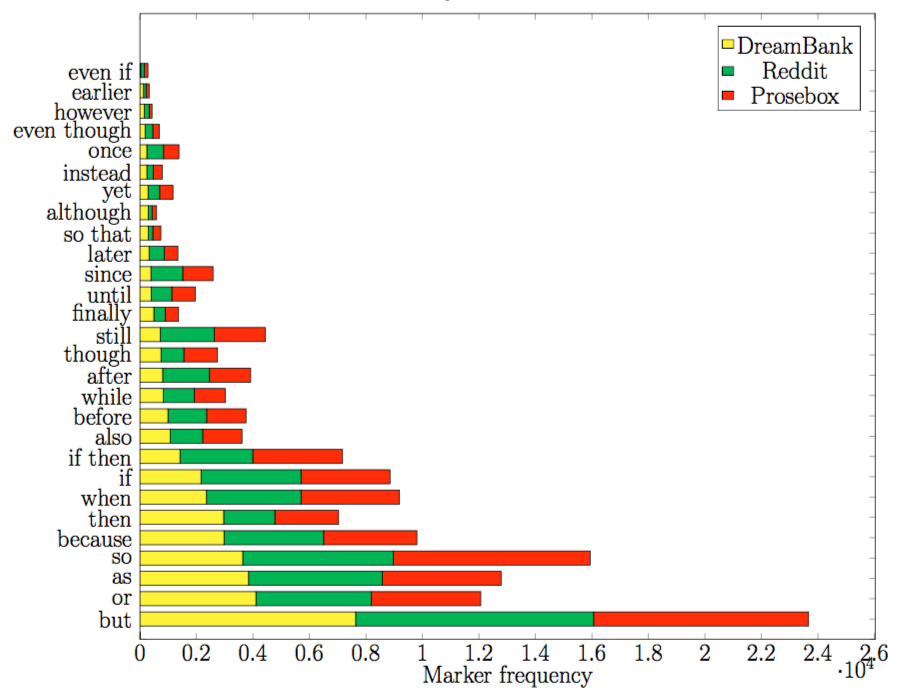
4.3. Bizarreness as dream characteristic
| Dataset | Accuracy | F-score |
| DreamBank | 0.23 | 0.32 |
| Prosebox | 0.37 | 0.42 |
| 0.37 | 0.43 |
5. Discussion
Acknowledgments
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
