Notes
[1] Queremos agradecer a Maciej Eder sus comentarios y
opiniones sobre varios detalles de este estudio. También queremos
agradecer a Christof Schöch sus comentarios y su ayuda en la
construcción del corpus.
[2]
También se ha utilizado la palabra estilometría en la
tradición española para realizar estudios sobre la frecuencia de
hapax, n-gramas o fragmentos concretos y
compararlos con corpus lingüísticos equilibrados, como en Madrigal
[Madrigal 2008]
[Madrigal 2009]. Sin embargo, los estudios de Madrigal
se diferencian notablemente de lo que hoy en día se considera
estilometría, tanto por los tipos de unidades analizadas, su
cantidad y su elección como por el corpus de comparación y su
evaluación. [4] Además de las Ocho comedias y ocho
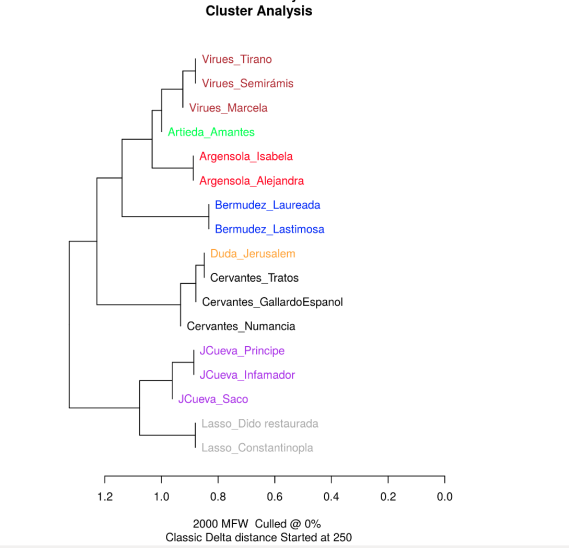
entremeses nunca representados, que vieron publicación
en vida del autor, el corpus de obras dramáticas de Cervantes se
amplía a El cerco de Numancia y a
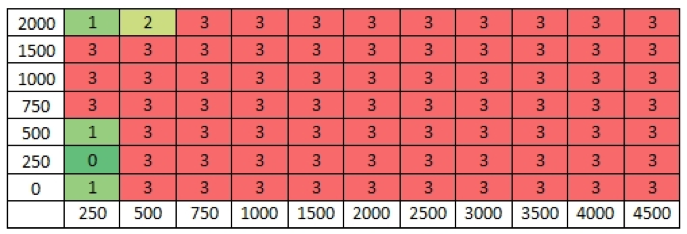
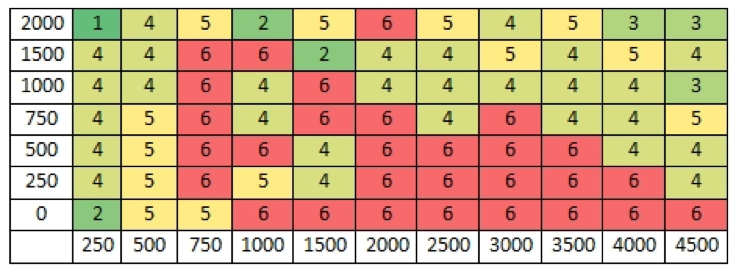
Los tratos de Argel, obras
conocidas desde el siglo XVIII, conservadas en copia manuscrita y
compuestas originalmente en torno a la década de 1580. Hay, además,
un buen número de obras de las que solo conocemos el título gracias
a las menciones que Miguel de Cervantes hizo en la Adjunta al Viaje de
Parnaso y que permanecen, todavía, perdidas.
[5] Esto puede tenderse a olvidar si se trabaja con
textos en inglés o alemán, donde proyectos como TextGrid u Oxford
Text Archive ponen a disposición de cualquier
usuario miles de textos en varios formatos, entre ellos XML-TEI.
La situación es radicalmente opuesta para el español, donde el
XML-TEI ha sido menos utilizado y, de los principales proyectos
que lo han utilizado, ninguno ha puesto a disposición de la
comunidad investigadora el código originario (como es el caso
del proyecto TESO, Cervantes Virtual o Biblioteca Digital
Artelope).
[6] Esto no ha sido posible en algunos casos debido
a que algunos de estos autores escribieron solo una o dos
obras teatrales. El trabajo se preguntó también cómo
proceder con aquellos autores como Cervantes, Francisco de
la Cueva o Juan de la Cueva que escribirieron más obras
teatrales. Se decidió en este caso también utilizar
solamente tres textos de estos autores por varias razones:
en primer lugar porque eso hubiese multiplicado el trabajo
de preparación del corpus; en segundo lugar porque al
representar a algunos autores con una cantidad mucho mayor
de textos que los otros autores desequilibraría el corpus y
por lo tanto podría afectar a los resultados estilométricos.
Es un aspecto que nos gusaría estudiar en mayor detalle en
el futuro.
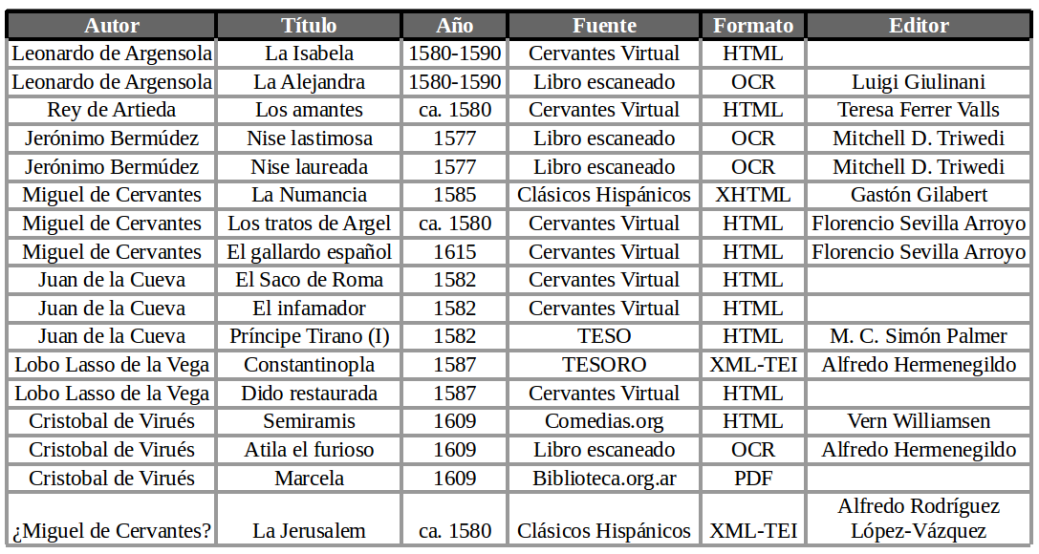
[7] Hemos preferido, en este orden: XML-TEI, XHTML
(ePUB), HTML, PDF, imagen.
[8] Para las fuentes en HTML hemos transformado el
texto de una manera similar a la que el grupo Computergestützte literarische
Gattungsstilistik trabaja [Schöch et al. 2014]. [9] Las ediciones del Cervantes Virtual ya habían sido
modernizadas de esta manera.
[10] Muestran diferencias importantes
entre géneros y es de esperar que las novelas del siglo XXI no
se comporten exactamente de la misma manera que las novelas de
siglos anteriores.
[11] No
es demasiado sorprendente si se tiene en cuenta lo complicado
que sigue resultando acceder a corpus literarios óptimos para
atribución de autoría. Un intento reciente en esta dirección es
el corpus publicado por Calvo Tello y Henny en 2015: https://github.com/cligs/textbox/tree/master/es. [12] En caso de que haya varios corpus de
una lengua (inglés y latín), el de prosa no está marcado y el de
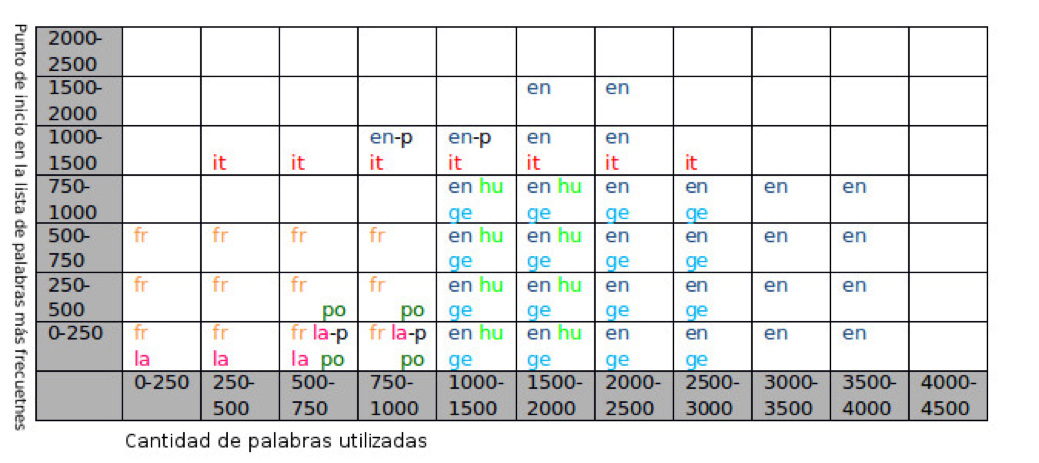
poesía está marcado con un guión y la letra p.
Estamos abiertos a sugerencias sobre la manera de visualizar
estos datos sin perder información.
[13] Además del dato numérico,
colocamos colores para que sea más fácilmente reconocible al ojo
humano
[14] Hemos utilizado la versión 0.6.2.4.
Queremos agradecer a los diseñadores de este software su
trabajo, documentación, matenimiento y docencia. Stylo permite que filólogos y
humanistas en general puedan utilizar complejos procedimientos
estadísticos para responder a preguntas básicas sobre los
textos, sin tener que afrontar el desarrollo de cientos de
líneas de código de tratamiento estadístico de textos. Nos
gustaría reconocer y valorar su enorme aportación a las
Humanidades Digitales, así como recomendar su uso a otros
investigadores.
[15] Es decir, que de la lista original de palabras más
frecuentes se utilizan aquellas que estarían entre la posición 251 y
2250.
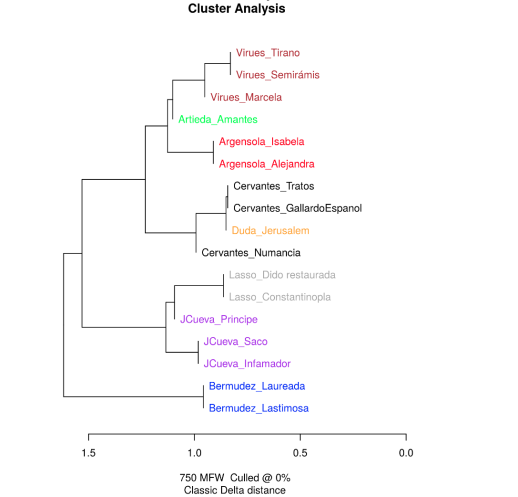
[16] Como explicación de esta visualización,
observamos tres ramas principales: Una en la esquina superior
izquierda que engloba los textos de Lasso y Juan de la Cueva; una
superior derecha donde aparecen los textos de Bermúdez; una tercera
inferior que engloba al resto de autores: en ella Cervantes forma su
propia subrama; Virués Artieda y Argensola aparecen en la otra
subrama.
[17] Los diferentes métodos de
aprendizaje automático utilizan técnicas de evaluación que suelen
requerir la división de los datos en varios sets: de aprendizaje, de
prueba y de implementación. Nuestro corpus no contiene la suficiente
cantidad de texto como para permitir que el sistema aprenda de
varios textos los rasgos de un autor, probarlo con otro y finalmente
aplicarlo. Ni siquiera si tuviésemos todos los textos escritos por
estos autores podríamos utilizar una metodología así ya que algunos
de los autores escribieron, únicamente, un par obras
teatrales.
[18] Es
decir, que utiliza las palabras que estarían en los rangos desde el
251 hasta el 500 en la lista de palabras más frecuentes.
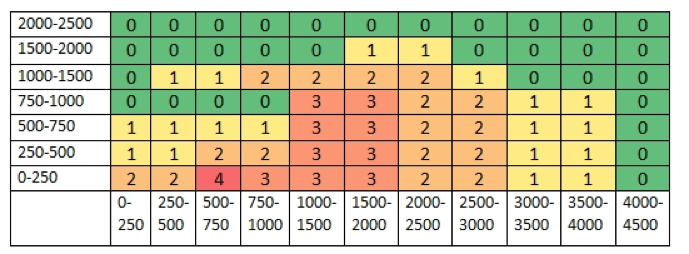
[19] Sabemos que nuestro
corpus es mucho menor y que es teatro en verso. Pero teniendo en
cuenta la total falta de este tipo de trabajos para el español,
consideramos que otros investigadores pueden utilizar algunos de los
rangos que aparecen como óptimos en la anterior tabla.
Works Cited
Antonucci 2014 Antonucci, Fausta. “La estructura dramática de La conquista
de Jerusalén por Godofre de Bullón: un análisis comparado con
La Numancia”. En Desde Artife. Estudios dedicados a Aldo Ruffinatto en el IV
Centenario de las Novelas Ejemplares, 97-108. Alessandria: Edizioni
dell'Orso, 2014.
Antonucci 2015 Antonucci, Fausta. “La estructura dramática del teatro cervantino de la primera
“época”: una propuesta de análisis”. Cuadernos AISPI 5 (2015): 131-46.
Arata 1989 Arata, Stefano. Los manuscritos teatrales (siglos XVI y XVII) de la Biblioteca de
Palacio. Pisa: Giardino, 1989.
Arata 1991 Arata, Stefano. “Loyola y Cepeda: Dos dramaturgos del Siglo de Oro en la Biblioteca de
Palacio”. Manuscrt.Cao IV (1991):
3-15.
Arata 1992 Arata, Stefano. “La
conquista de Jerusalén, Cervantes y la generación teatral de 1580”.
Criticón 54 (1992): 9-112.
Arata 1996 Arata, Stefano. “Teatro y coleccionismo teatral a finales del siglo XVI (el conde de
Gondomar y Lope de Vega)”. Anuario de Lope de
Vega 2 (1996): 7-24.
Arata 1997 Arata, Stefano. “Notas sobre La conquista de Jerusalén y la transmisión manuscrita del
primer teatro cervantino”. Edad de Oro
16 (1997): 53-66.
Argamon 2008 Argamon, Shlomo. “Interpreting Burrows’s Delta: Geometric and Probabilistic
Foundations”. En Literary and Linguistic
Computing 23 (2) (2008): 131-47.
Argamon et al. 2003 Argamon, Shlomo, Moshe
Koppel, Jonathan Fine, y Shimoni Anat Rachel. “Gender,
Genre, and Writing Style in Formal Written Texts”, En Text and Talk, no. 23 (2003): 321-346.
Baras Escolá 2010 Baras Escolá, Alfredo.
“Los textos de Cervantes. Teatro”. Anales Cervantinos 42 (2010): 73-88.
Bernaldo de Quirós Mateo 2011 Bernaldo de
Quirós Mateo, José Antonio. “La Celestina: Adiciónes
primeras amplificadas con adiciónes secundas. Consequencias para la
atributión de la autoría”. Etiópicas,
no. 7 (2011): 87-104.
Brioso Santos 2009 Brioso Santos, Héctor.
“A propósito de la historicidad de La conquista de
Jerusalén: los cuatro milagros de la primera cruzada”. Anuario de Estudios Cervantinos 5 (2009):
101-24.
Brioso Santos 2010 Brioso Santos, Héctor.
“Análisis métrico de La conquista de Jerusalén por
Godofre de Bullón de... ¿Miguel de Cervantes?”
Cuatrocientos años del Arte Nuevo de hacer comedias de Lope
de Vega [Actas] 2 (2010): 287-94.
Brioso Sánchez y Brioso Santos 2007 Brioso
Sánchez, Máximo, y Brioso Santos, Héctor. “De Heliodoro a
Tasso y a ¿Cervantes?”
Philología Hispalensis 21 (2007): 155-72.
Burguillo 2013 Burguillo, Francisco Javier.
“Guerra y milicia en los albores del “Arte nuevo”: la
“Comedia del saco de Roma” (1579) de Juan de la Cueva”. En Del pensamiento al texto. Textualización del saber en el
Renacimiento español, 23-60. Madrid: Academia del Hispanismo,
2013.
Burrows 2002 Burrows, John. “‘Delta’: A Measure of Stylistic Difference and a Guide to Likely
Authorship”. En Literary and Linguistic
Computing 17 (3) (2002): 267-87.
Calvo Tello et al. 2015 Calvo Tello, José,
Christof Schöch, Nanete Rißler-Pipka, y Tobias Kraft. 2015. “Humanidades Digitales y estudios hispánicos en Alemania”. Voy y Letra 26 (1) (2015): 45-61.
Camamis 1977 Camamis, George. Estudios sobre el cautiverio en el Siglo de Oro.
Madrid: Editorial Gredos, 1977.
Canavaggio 2000 Canavaggio, Jean. “De un Lope a otro Lope: Cervantes ante el teatro de su
tiempo”. Anuario de Lope de Vega 6
(2000): 51-60.
Canavaggio 2005 Canavaggio, Jean. Cervantes. Espasa. Madrid, 2005.
Castillo 2012 Castillo, Moisés R. “Espacios de ambigüedad en el teatro cervantino: La conquista
de Jerusalén y los dramas de cautiverio”. Cervantes: Bulletin of the Cervantes Society of America 32, 2
(2012): 123-42.
Cerezo Soler 2013 Cerezo Soler, Juan. ““La Conquista de Jerusalén” y la literatura de Cervantes.
Nuevas semejanzas que respaldan su autoría”. En
Festina lente. Actas del II congreso internacional Jóvenes Investigadores
del Siglo de Oro (JISO 2012), editado por Carlos Mata Induráin,
Adrián J. Sáez, y Ana Zúñiga Lacruz. Pamplona: Servicio de Publicaciones de la
Universidad de Navarra, 2013.
http://dadun.unav.edu/handle/10171/29457.
Cerezo Soler 2014 Cerezo Soler, Juan. ““La Conquista de Jerusalén” en su contexto: sobre el personaje
colectivo y una vuelta más a la atribución”. Dicenda: cuadernos de filología hispánica 32 (2014): 33-49.
Eder 2012 Eder, Maciej. “Mind
Your Corpus: Systematic Errors in Authorship Attribution”. En Digital Humanities 2012: Conference Abstracts,
Hamburg, Hamburg Univ. Press (2012): 181-85.
Eder 2013a Eder, Maciej. “Does
Size Matter? Authorship Attribution, Small Samples, Big Problem”. En
Digital Scholarship in the Humanities 30 (2)
(2013): 167-182.
Eder 2013b Eder, Maciej. “Bootstrapping Delta: a safety-net in open-set authorship
attribution”. En Digital Humanities 2013:
Conference Abstracts, Lincoln: University of Nebraska-Lincoln
(2013): 169-172.
Eisenberg 2003 Eisenberg, Daniel. “¿Qué escribió Cervantes?” En Sobre
Cervantes, editado por Martínez Torrón, Diego, 9-26. Alcalá de
Henares: Centro de Estudios Cervantinos, 2003.
García-Bermejo Giner 2013
García-Bermejo Giner, Miguel. “Estando letras y armas en su
punto: el teatro y los aledaños del poder en España a fines del siglo
XVI”. En Del pensamiento al texto.
Textualización del saber en el Renacimiento español, 85-122. Madrid:
Academia del Hispanismo, 2013.
Jannidis y Lauer 2014 Jannidis, Fotis, y
Gerhard Lauer. “Burrows’s Delta and Its Use in German
Literary History”. En Distant Readings.
Topologies of German Culture in the Long Nineteenth Century,
Rochester: Camden House (2014): 29-54.
Jockers 2013 Jockers, Matthew L. Macroanalysis - Digital Methods and Literary History.
Champaign, IL: University of Illinois Press (2013).
Kahn 2010 Kahn, Aaron M. “Towards a theory of attribution: Is La conquista de Jerusalén by Miguel de
Cervantes?”
Journal of European Studies 40 (2) (2010):
99-128.
Kestemont et al. 2012 Kestemont, Mike, Kim
Luyckx, Walter Daelemans, y Thomas Crombez. “Cross-Genre
Authorship Verification Using Unmasking.” En English Studies 93 (3) (2012): 340-56.
López 2011 López, Freddy. “Donde se muestran algunos resultados de atribución de autor en torno a la
obra cervantina (Wherein are Shown some Results of Autorship Attribution to
Cervantes’ Work).” En Revista Colombiana de
Estadística 34 (1) (2011): 15-37.
Madrigal 2008 Madrigal, José Luis. “Notas sobre la autoría del Lazarillo”. En Revista de Literatura Española Medieval y del Renacimiento
(LEMIR), 12 (2008): 137-236.
Madrigal 2009 Madrigal, José Luis. “Tirso, Lope y el Quijote de Avellaneda”. Revista de Literatura Española Medieval y del Renacimiento
(LEMIR), 13 (2009): 191-250.
Montero Reguera 1994-1995 Montero Reguera, José.
“Reseña a Stefano Arata, “La conquista de Jerusalén
[...]””. Manuscrt.Cao VI (1994-1995):
83-87.
Montero Reguera 1995-1997 Montero Reguera, José.
“¿Una nueva obra teatral cervantina? Notas en torno a
una reciente atribución”. Anales
Cervantinos 33 (1995-1997): 355-66.
Rey Hazas 1992 Rey Hazas, Antonio. “Cervantes y Lope ante el personaje colectivo: La Numancia
frente a Fuenteovejuna”. Cervantes y el teatro.
Cuadernos de Teatro Clásico 7 (1992): 69-91.
Rey Hazas 1994 Rey Hazas, Antonio. “Las comedias de cautivos de Cervantes”. Los imperios orientales en el teatro del Siglo de Oro [Actas
de las XVI Jornadas de Teatro Cásico], 1994, 29-56.
Rey Hazas 1999 Rey Hazas, Antonio. “Cervantes se reescribe: Teatro y Novelas Ejemplares”.
Criticón 76 (1999): 119-64.
Rey Hazas 2005 Rey Hazas, Antonio. Poética de la libertad y otras claves cervantinas.
Madrid: Eneida, 2005.
Rißler-Pipka 2016 Rißler-Pipka, Nanette.
“Avellaneda y los problemas de la identificación del
autor. Propuestas para una investigación con nuevas herramientas
digitales”. En Ehrlicher, Hanno. El otro Quijote. La continuación de
Avellaneda y sus efectos. Mesa Redonda-Universität Augsburg, Augsburg (2016).
(Manuscrito)
Rodríguez López-Vázquez 2011 Rodríguez
López-Vázquez, Alfredo. “La Jerusalén de Cervantes: Nuevas
pruebas de su autoría”. Artifara: Revista de
Lenguas y Literaturas ibéricas y latinoamericanas 11 (2011).
Rojo Alique 1996-1998 Rojo Alique, Pedro C.
“Notas acerca del Catálogo de manuscritos de la
Biblioteca del Palacio Real de Madrid”. Manuscrt.Cao VII (1996-1998): 83-131.
Rybicki y Eder 2011 Rybicki, Jan, y Maciej Eder.
“Deeper Delta across Genres and Languages: Do We Really
Need the Most Frequent Words?” En Literary and
Linguistic Computing 26 (3) (2011): 315-21.
Schöch 2014 Schöch, Christof. “Corneille, Molière et les autres. Stilometrische Analysen zu
Autorschaft und Gattungszugehörigkeit im französischen Theater der
Klassik”.
Literaturwissenschaft im digitalen
Medienwandel. Beihefte von Philologie im Netz 7, 2014: 130-157.
http://web.fu-berlin.de/phin/beiheft7/b7t08.pdf.
Seroussi et al. 2014 Seroussi, Yanir, Ingrid
Zukerman, y Fabian Bohnert. “Authorship Attribution with
Topic Models”. En ACL Anthology 40 (1)
(2014): 269-310.
Vaccari 2006 Vaccari, Debora. “Aproximación al contenido de una carpeta inédita de la
Biblioteca Nacional de Madrid (Ms/14612/9)”. En Campus stellae: haciendo camino en la investigación literaria,
editado por Fernández López, Dolores, Domínguez Pérez, Mónica, y
Rodríguez-Gallego, Fernando, 1:466-74. Santiago de Compostela, 2006.
Wrisley 2016 Wrisley, David Joseph. “Modeling the Transmission of Al-Mubashshir Ibn Fātik’s Mukhtār
Al-Ḥikam in Medieval Europe: Some Initial Data-Driven Explorations”.
En Journal of Religion, Media and Digital Culture
Special Issue “Digital Humanities in Jewish, Christian and
Arabic/Islamic Ancient Traditions”. (5) (2016).
Zimic 1992 [Zimic 1992] Zimic, Stanislav. El teatro de Cervantes. Madrid: Castalia, 1992.
van Dalen-Oskam y van Zundert 2007 van
Dalen-Oskam, Karina, y Joris van Zundert. “Delta for Middle
Dutch: Author and Copyist Distinction in “Walewein””. En Literary and Linguist Computing 22 (3) (2007):
345-62.