Notes
[1] Les statistiques portant sur la totalité historique du
matériel publié dans le monde varient. On parle d’environ 30 MK de livres,
750 MK d’articles, 25 MK de chansons, 500 MK images, 3 MK de vidéos ou
programmes et 100 MK de pages internet. Dans une étude de 2011 [Thielens 2011], on comptait environ 285 exabits de données non
structurées de divers types (images, son, textes, etc.). Pour un état de
l’accroissement des données textuelles, voir : [Xiao 2008]Xiao, 2008. [3] Ce qui n’est pas sans soulever de
nombreuses questions politiques et juridiques. Sur cette question, voir [Jeanneney 2005]. [4] Les analyses
philologiques du terme « texte » renvoient d’ailleurs en tout premier
lieu au tissu et au tissage : « Textus, du participe
passé de textere, est ce qui a été tissé, tressé,
entrelacé, construit ; c’est une trame. »
[Cerquiligni 1989, 59]. [5]
Wikipédia le définit directement de cette
manière : « Un livre (sens le plus courant) est un
ensemble de pages reliées entre elles et contenant des signes destinés à
être lus. » (https://fr.wikipedia.org/wiki/Livre) [6] Ces propriétés matérielles du texte sont
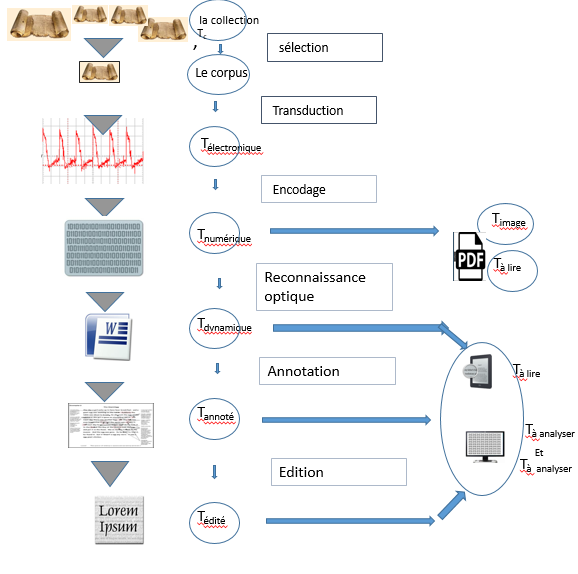
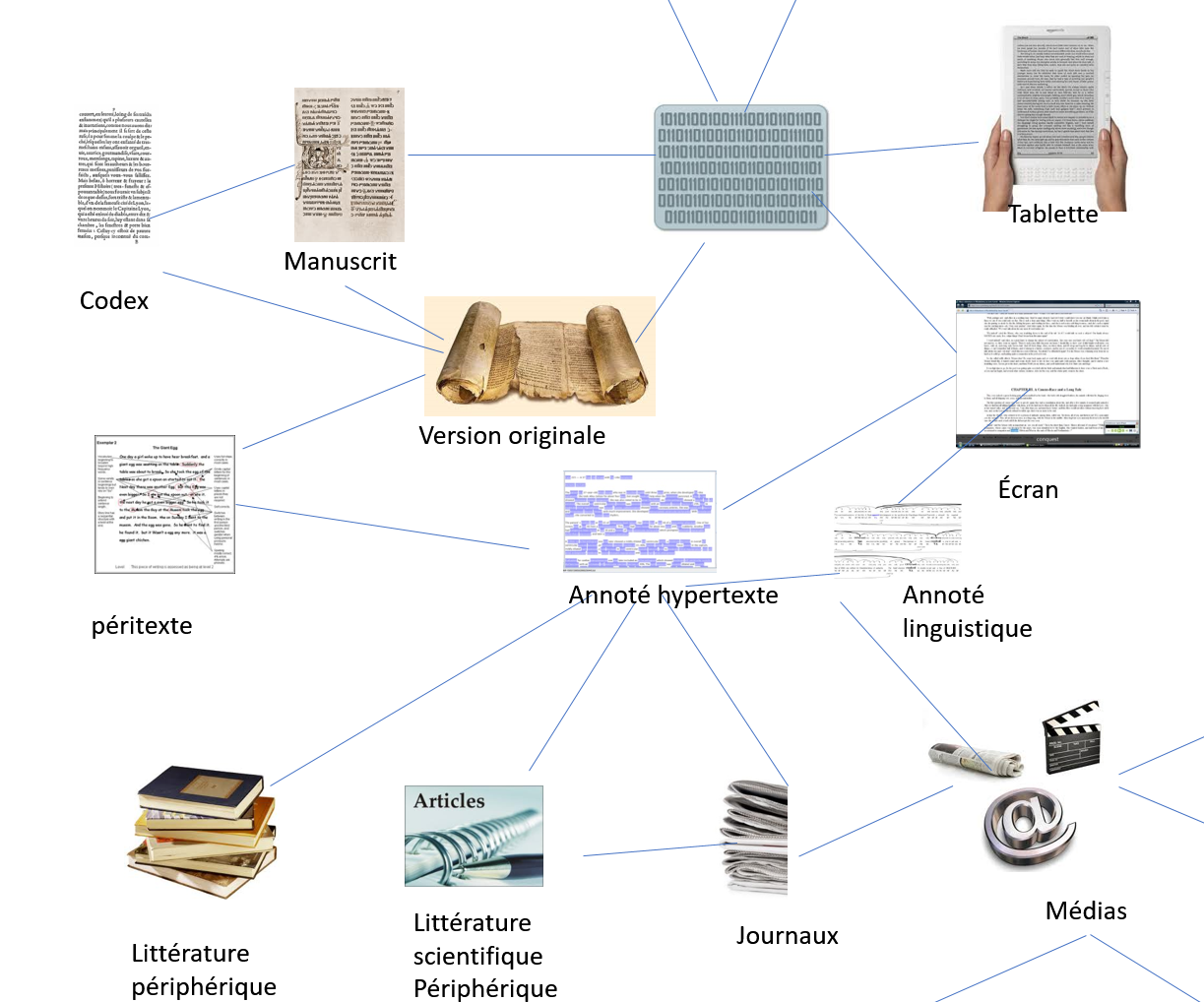
importantes. De nombreux historiens et théoriciens ont montré comment, à
travers les siècles, la lente transformation du support physique du texte a
été déterminante sur sa lecture et son analyse. Un texte inscrit sur la
pierre ne pouvait être lu qu’oralement. Un manuscrit de copiste exigeait un
lecteur spécialisé. Le codex ouvrait à un public plus large. L’insertion
d’une gravure et d’une image orientait l’interprétation. La forme
livre impose une lecture solitaire, séquentielle, un rythme
spécifique. Elle contraint aussi l’analyse qui entre autres permet le
soulignement, le commentaire, l’annotation (marginalia), etc. Chacun de ces types de supports physiques
touchait de manière propre l’accès, le contenu signifiant du texte. Et
aujourd’hui, le support électronique n’est pas sans offrir aussi une
diversité de manipulations originales et spécifiques (déroulement,
hyperliens, gigogne, archivage, transmission, affichages multiples, etc.)
qui à leur tour ne sont pas sans affecter la lecture et l’analyse.
[9]
Sur ce plan, une image peut aussi être numérisée et devenir une suite
d’inscriptions électroniques. Aucun humain ne peut, du moins normalement,
y reconnaitre une image comme telle.
[10] Cependant, selon la qualité de la
conversion, il est possible formellement et matériellement de reproduire
de manière fidèle le signal analogique original. Certaines techniques de
filtrage du bruit permettent de stabiliser, de nettoyer et de rendre plus
précis le signal entrant (cf. l’effet Dither : effet de réverbération du
bruit de la mécanique du moteur sur la numérisation).
[11] La manutention de
certains documents anciens peut exiger des technologies plus fines, qui
éviteront de les fragiliser davantage : par exemple, éviter de forcer la
reliure, la délicatesse du changement de page, etc. L’ampleur et la
finalité de la numérisation exigent des scanneurs appropriés : manuels ou
automatiques. Dans les grands projets, la saisie est confiée à des
entreprises spécialisées via des sous-traitances (outsourcing). Les plus simples sont à couverts plats ou en
V, les plus sophistiqués sont à angles, ou même robotiques. Le choix d’un
type particulier de scanneur dépendra des fins poursuivies. Il ne sera
pas le même pour copies dactylographiées à archiver et à envoyer, à
mettre sur Internet, ou pour ceux à inclure dans une collection de
bibliothèques patrimoniales ou à conserver pour la postérité.
[12] Par exemple, la qualité
des lentilles et la stabilité physique de l’appareil. Il existe divers
types de scanneurs, les uns plus sophistiqués que les autres, et leur
coût est évidemment lié à leur performance potentielle.
[13] Le noir et blanc doivent être
limités à des copies de travail. Il y a trop de perte d’informations.
Mieux vaut la couleur et avec la plus haute résolution et finesse
possible pour des fins de conservation. Il est toujours possible alors de
revenir à des copies de travail plus économiques en espace
mémoire.
[14]
On ne peut négliger les multiples sous-opérations impliquées dans une
numérisation. De nombreuses fonctionnalités logicielles peuvent assister
la numérisation et la rendre ergonomiquement plus facile. Par exemple, le
choix des types de pages, des sections de pages, des copies multiples, de
l’automatisation des fonctions, des outils d’édition, de l’ajustement des
couleurs, etc.
[15] La sémantique de ce code : il réfère aux deux grandes
classes de variations électriques de l’inscription électronique du
signal, soit le positif ou le négatif.
[16] Les autres formats classiques de sortie de l’image
sont le GIF (Graphics Interchange Format) et
le PDF (Portable Document Format). Pour la
numérisation académique, on utilisera surtout les formats TIFF, JPEG et
PDF. En fait, une combinaison des trois sera souvent utile selon la
multiplicité des usages faite des documents numérisés. Le format TIFF est
le format le plus compatible avec les multiples plateformes logicielles
et celui qui conserve le plus d’informations. Évidemment, il coûte cher
en espace mémoire, mais il assure une stabilité dans la conservation et
l’interchangeabilité logicielle. Le format JPEG est un format de
compression. Il est le plus populaire pour des documents à mettre sur
Internet et pour échanger. L’œil ne saisira pas la différence, mais pour
l’archivage, ou des agrandissements et des manipulations plus fines, ce
format sera problématique.
[19] Plus la
résolution est fine, meilleure est la précision de la copie électronique.
La résolution doit être haute si la finalité est la constitution
d’archives professionnelles ; elle peut être moins haute si la
numérisation n’est qu’une étape vers la production d’un texte vivant
(soumis au ROC). Le choix de la résolution sera préférablement haut
(autour de 1000 dpi) pour de l’archivage patrimonial, mais pour une
reconnaissance optique de caractères, quelque 400 dpi suffisent.
[20] Il est intéressant de noter que l’expression
« numérique » associée à « clavier » renvoie habituellement
au pavé numérique, c’est-à-dire le clavier avec des chiffres. Le clavier
ordinaire d’un ordinateur est une technologie mécanique qui transforme
une pression effectuée sur une touche en un signal électrique qui, à son
tour, est transformé en un code numérique. Lorsque les textes à copier
sont complexes, la saisie passe souvent par l’intermédiaire de plusieurs
personnes. Elles encoderont manuellement, en parallèle et de manière
comparée, le texte-image (ou le texte source lui-même) pour assurer la
plus grande fidélité du texte vivant avec l’original.
[21] Il faut
distinguer le jeu de caractères codés avec leur représentation en bits.
Par exemple, le code ASCII est lui-même encodé en 8 bits dans la norme
ISO 8859.
[22] Et dans ce cas, il faudra des
stratégies complexes de vérification et de correction : par exemple,
faire des copies parallèles qui sont comparées et co-corriger.
[23] Les logiciels de ROC ne travaillent jamais sur le
document papier d’origine ; ils en font toujours, mais de manière
transparente, une copie image, et c’est cette image via la représentation
numérique des configurations lumineuses qui est soumise au logiciel de
reconnaissance.
[24] Le format TXT
élimine tous les marqueurs et ne garde que les espaces entre les mots
alors que le RTF en conserve quelques marqueurs importants (comme les
paragraphes et les italiques).
[25] Il est intéressant de noter la
métonymie sous-jacente à cette nomination de « logiciel de traitement
de textes ». WordTM, par exemple, ne traite pas du texte
sémiotique, mais des signes linguistiques encodés de manière standard.
Pour ce logiciel, il n’y a pas de différence informatique entre « la
klr ok kf prp oi klr » et « Il lit ce livre au lit ». Les deux
sont des suites de signes linguistiques même si la première suite n’a
aucun sens.
[26] Le texte
est quelques fois appelé « vivant » ou en anglais « living »
par les entreprises informatiques spécialisées en logiciels ROC. Mais le
terme dynamique semble utilisé le plus souvent.
[27] Un nettoyage et un
filtrage sont souvent par la suite nécessaires. Mais ces tâches peuvent
être assistées par des outils informatiques. Par exemple, un extracteur
de lexique peut fournir la liste des chaînes de caractères formant les
« mots » mal identifiés.
[31] Une modification de XML a donné lieu (en 2007) à XHTML,
mais ce dernier a été ensuite abandonné.
[32] Une ontologie est une spécification
explicite et formelle d’une conceptualisation partagée d’un domaine
d’intérêt. Les concepts y sont traditionnellement organisés en un graphe
dont les relations peuvent être soit des relations sémantico-logiques,
soit des relations de composition et d’héritage (conformément au
paradigme objet). L’interprétation des ontologies est souvent de nature
épistémique, dans la mesure où elles représentent des
connaissances.
[34] Il y a toujours une théorie latente qui opère dans la
préparation du balisage. Comme le dit M. Sperberg-McQueen, « Markup reflects a theory
of text »
[Sperberg-McQueen 1991, 34]. [35] Les multiples projets d’annotation linguistique
constituent à ce titre de bons exemples.
[37] Sur Wikipédia, l’accès aux textes de Kierkegaard (https://en.wikipedia.org/wiki/Søren_Kierkegaard) se fait par
plusieurs sites interreliés où textes, paratextes et péritextes sont mis
en interrelation par des commentateurs annotateurs et fort probablement
revisés par la fondation Kierkegaard. [41]
Les premières recherches menées par Dillon ont démontré d’importantes
différences dans les deux types d’expérience textuelle, notamment en ce
qui a trait à la rapidité, à la précision, à la fatigue visuelle ainsi
qu’à la compréhension [Dillon 1992]. [42] Pour [Kelly 2006], les liens
hypertextes et les marqueurs représentent deux des plus importantes
inventions des cinquante dernières années. Works Cited
Ackerman et Goldsmith 2011 Ackerman, Rafaket,
Goldsmith, Morris (2011). “Metacognitive regulation of text
learning: On screen versus on paper”. Journal of
Experimental Psychology: Applied, 17-1 (2011): 18-32.
Adam 1999 Adam, Jean-Michel. Linguistique textuelle: des genres de discours aux textes. Paris, Nathan
(1999).
Baccino 2004 Baccino, Thierry. La lecture électronique: De la vision à la compréhension. Grenoble,
Presses Universitaires de Grenoble (2004).
Bird et Liberman 2001 Bird, Steven, Liberman, Mark.
“A Formal Framework for Linguistic Annotation (revised
version)”. Speech Communication, 33, 1-2
(2001): 23-60.
Buitelaar, Cimiano et Magnini 2005 Buitelaar, Paul,
Cimiano, Philipp, Magnini, Bernardo, “ Ontology Learning from
text: An Overview ”. In Buitelaar, Paul, Cimiano, Philipp, Magnini,
Bernardo Magnini (dir.). Ontology Learning from Text: Methods,
Evaluation and Applications. Amsterdam, IOS Press (coll. “Frontiers in Artificial Intelligence and Applications”): 3-12
(2005).
Cerquiligni 1989 Cerquiligni, Bernard. Éloge de la variance : histoire critique de la philologie.
Paris, Éditions du Seuil (1989).
DeRose 1999 DeRose, Steven J., van Dam, Andries,
“Document structure and markup in the FRESS Hypertext
System.”
Markup Languages 1(1), Winter 1999: 7-32.
DeStefano et LeFevre 2007 De Stefano Diana, Lefevre
Jo-Anne. “Cognitive load in hypertext reading: A review”.
Computers in Human Behavior. 23-3 : 1616-1641 (2007).
Desclés 1996 Desclés, Jean-Pierre. “Cognition, compilation, langage”. In Chazal, Gérard,
Terrasse, Marie-Noëlle (dir.). Philosophie du langage et
informatique. Paris, Hermès: 103-145 (1996).
Dillon 1992 Dillon, Andrew. “Reading from Paper Versus Screens: a Critical Review of the Empirical
Literature”. Ergonomics, 35-10 (1992):
1297-1326.
Eberle Sinatra et Forest 2016 Eberle Sinatra,
Michael, Forest, Dominic. “Lire à l’ère du numérique:
Le nénuphar et l’araignée de Claire Legendre”.
“Sens public”. 22 décembre 2016 :
http://www.sens-public.org/article1230.html.
Eberle Sinatra et Vitali-Rosati 2014 Eberle
Sinatra, Michael, Vitali-Rosai, Marcello (dir.). Pratiques de
l’édition numérique. Montréal, Presses de l’Université de Montréal, coll.
“ Parcours numérique ” (2014).
Foucault 1969 Foucault, Michel. Archéologie du savoir. Paris, Gallimard (1969).
Gabler 2010 Gabler, Hans W. “Theorizing the Digital Scholarly Edition”. Literature
Compass. 7-2 (2010): 43-56.
Genette 1979 Genette, Gérard. Introduction à l’architexte. Paris, Seuil (2001).
Genette 1987 Genette, Gérard. Seuils. Paris, Le Seuil (1987).
Goldfarb 1981 Goldfarb, Charles F. “A Generalized Approach to Document Markup”. In Proceedings of the ACM SIGPLAN-SIGOA Symposium on Text
Manipulation. New York, ACM (1981).
Habert et al. 1997 Habert, Benoît, Nazarenko, Adeline,
Salem, André, et al. Les
linguistiques de corpus. Paris, Armand Colin (1997).
Halliday et Hasan 1976 Halliday Michael, Hasan,
Ruqaiya. Cohesion in English. Londres, Longman
(1976).
Jeanneney 2005 Jeanneney, Jean-Noël. “Quand Google défie l’Europe”. Le
Monde. 22 janvier 2005.
Jeanneney 2010 Jeanneney, Jean-Noël. “Quand Google défie l’Europe”. Plaidoyer
pour un sursaut. Fayard, Mille et une nuits, Paris (2010).
Jeanneret 2014 Jeanneret, Yves. Critique de la trivialité. Les médiations de la communication, enjeu
de pouvoir. Paris, Éd. Non Standard (2014).
Kulkarni et Rokade 2014 Kulkarni, Kiran C., Rokade,
Shashikant. “Review on Automatic Annotation Search From Web
Database International Journal of Emerging Technology and Advanced Engineering
Website”:
www.ijetae.com, 4-1
(2014).
Ma, Audibert et Nazarenko 2009 Ma, Yue, Audibert, Laurent,
Nazarenko, Adeline. “Ontologies étendues pour l’annotation
sémantique”. In Gandon, Fabien L. IC2009: Actes des
20e Journées francophones d’ingénierie des connaissances. Hammamet, Tunisie,
Mai 25-29. Grenoble, Presses universitaires de Grenoble (2009).
Mangen, Walgermo et Bronnick 2013 Mangen, Anne,
Walgermo, Bente R., Bronnick, Kolbjørn. (2013) “Reading linear
texts on paper versus computer screen: Effects on reading comprehension”.
International Journal of Educational Research, 58
(2013): 61-68.
Marshall 1998 Marshall, Catherine. “The Future of Annotation in a Digital (Paper) World.”
presented at the 35th Annual SGLIS Clinic: Successes and Failures of Digital
Libraries, University of Illinois at Urbana-Champaign (1998).
Mayaffre 2002 Mayaffre, Damon.
Les corpus réflexifs: entre architextualité et hypertextualité.
Corpus, 1 (2002) :
https://corpus.revues.org/11.
Meyers 2005 Meyers, Adam. “Introduction to Frontiers in Corpus Annotation II Pie”. In The Sky Proceedings of the Workshop on Frontiers in Corpus
Annotation II: Pie in the Sky: 1-4 (2005).
Moretti 2013 Moretti, Franco. Distant Reading. Londres et New York, Verso (2013).
Morrison, Popham et Wikander 2013 Morrison, Alan,
Popham, Michael, Wikander, Karen. “Creating and Documenting
Electronic Texts”.
AHDS Guides to Good
Practice.
Oxford Text Archive (2013):
http://ota.ox.ac.uk/documents/creating/cdet/.
Mueller 2008 Mueller, Martin. “Digital Shakespeare, or Toward a Literary Informatics”. Shakespeare, 4-3: 284-301 (2008).
Noyes et Garland 2008 Noyes, Jan, Garland, Kate. “Computer- vs. Paper-based Tasks: Are They Equivalent?”.
Ergonomics. 51-9 (2008): 1352-1375.
Pincemin 2007 Pincemin, Bénédicte. “Introduction”. Corpus.
“Interprétation, contextes, codage”. 6 (2007): 5-15.
Rastier 2001 Rastier, François. Arts et sciences du texte. Paris, Presses universitaires de France
(2001).
Rastier 2011 Rastier, François. La mesure et le grain: sémantique de corpus. Paris, Honoré Champion
(2011).
Reid 1980 Reid, Brian. “A High-Level
Approach to Computer Document Formatting”. In Proceedings of the 7th Annual
ACM Symposium on Programming Languages. New York, ACM (1980).
Renear, Mylonas et Durand 1996 Renear, Allen H.,
Mylonas, Elli, Durand, David. “Refining our Notion of What Text
Really Is: The Problem of Overlapping Hierarchies”. In Ide, Nancy, Hockey,
Susan (dir.). Research in Humanities Computing. Londres,
Oxford University Press (1996).
Smith 1987 Smith, Joan M. “The
Standard Generalized Markup Language (SGML) for Humanities Publishing”.
Literary and Linguistic Computing. 2-3: 171-75
(1987).
Souchier et Jeanneret 1999 Souchier, Emmanuel,
Jeanneret, Yves. “Pour une pratique de “l’écrit
d’écran””. Xoana. 6: 98-99 (1999).
Sperberg-McQueen 1991 Sperberg-McQueen,
Michael. “Text in the Electronic Age: Textual Study and Text
Encoding, with Examples from Medieval Texts”. Literary
and Linguistic Computing. 6-1: 34-46 (1991).
Tolzmann, Hessel et Peiss 2001 Tolzmann, Don
Heinrich, Hessel, Alfred, Peiss, Reuben. The Memo of
Manki. New Castle, Oak Knoll Press (2001).
Vandendorpe 2009 Vandendorpe, Christian. From Papyrus to Hypertext. Urbana-Champaign, Illinois
University Press (2009).
Veronis 2000 Veronis Jean. “Annotation automatique de corpus: état de la technique”. Ingénierie des langues. Hermes,
111-118 (2000): 1-52.
Virbel 1993 Virbel, Jacques. “Reading and Managing Texts on the Bibliothèque de France Station”. In
Delany, Paul, Landow, George P. (éd.). The Digital Word: Text
Based Computing in the Humanities. Cambridge, MIT Press (1993).
Weinnreich 1972 Weinnreich, Uriel. Explorations in Semantic Theory. Berlin, De Gruyter Mouton
(1972).
Wästlund, Reinikka, Norlander et Acher 2005 Wästlund, Erik, Reinikka, Henrik, Norlander, Torsten, Acher, Trevor. “Effects of VDT and Paper Presentation on Consumption and Production
of Information: Psychological and Physiological Factors”. Computers in Human Behavior. 21 (2005): 377 sq.
Xiao 2008 Xiao, Richard Z. “Well-known and influential corpora”. In Lüdeling, Anke, Merja, Kyto
(dir.). Corpus Linguistics: An International Handbook,
vol. 1. Berlin, De Gruyter Mouton (2008): 383-457.