The William Blake Archive emphasizes accuracy and objectivity. The photographed or
scanned images are made faithful to their original objects in scale, color, and
detail. The editors’ notes are largely bibliographic and informative. The
illustration descriptions consist of precise observations deliberately void of
interpretation. The transcriptions are as diplomatic as the digital medium allows.
And the explicit relationships between objects in the Archive are material; one can
see, for example, copies of prints from the same relief-etched copper plate, or a
design carried from a water color drawing to an engraved illustration. The scholar
must be free to make his or her own interpretations.
Since beginning to redesign the back end and front end of the site, the editors and
staff have realized that these relationships encoded in our data should be made more
accessible and that even more kinds of relationship should be added. The challenge
has been to decide which ones conform to our emphasis on accuracy and objectivity.
In a neutral presentation of art and its contextual information, we cannot tell the
scholar that object X relates to object Y because they embody the same theme. That
would impose on him or her our own interpretation. But we can say that X relates to
Y because they contain some of the same text.
In this paper, we discuss the difficult task of digitally presenting more kinds of
relationships in the Archive while remaining objective. We explain how the task has
compelled us to reevaluate Blake’s methods and re-encode the connections amongst his
works accordingly. We describe planned enhancements to our tools used for
representing and displaying these connections — enhancements that would benefit all
archives, not just the Blake Archive. And finally, we gesture towards further
research into the philosophical context of Blake's practice of making artworks
related to each other and into the idea of archival relationship in general.
“Copying Correctly is the only School to the Language of
Art”: Specification
In 1993, the editors of the William Blake Archive conceived it to “provide
unified access to major works of visual and literary art that are highly
disparate, widely dispersed, and more and more often severely restricted as a
result of their value, rarity, and extreme fragility” [
Eaves et al.].
Highly disparate but not completely, since the Archive was designed to enable
users to perceive relations between Blakean objects. But given the vastness of
Blake’s multimedia output, these relationships, although encoded in our data,
might not be readily apparent to users. Therefore, a primary goal of the back
and front-end redesign of the William Blake Archive has been to clarify and make
easily navigable the numerous types of relationships that the editors have
identified within Blake’s corpus.
The problem of representing relationships in a digital archive is of course
nothing new; indeed, it’s a fundamental one when designing an archive. But there
are varying forms of the problem, which Manuel Portela summarizes well [
Portela 2014, ¶32]:
- representation of relationships between original materials and their
digital surrogates;
- representation of relationships of digital objects to themselves and
with each other; and
- representation of relationships between digital objects and the users
interacting with them.
Each of these must be taken up and resolved to create a proper digital
archive. Depending on the primary function of the archive, one form of the
problem may raise more challenges than another. The
Sentences Commentary Text Archive, to take a unique example,
represents “organic relationships”, a term its editor Jeffrey
Witt inherits and takes to mean relationships encoded in metadata that “can be tracked and made discoverable by future
users”
[
Witt 2016, ¶16]. The primary function of this archive is to provide access to metadata
about commentary on a literary work. Naturally, the designer must work to encode
relationships falling under Portela’s categories 2 and 3. The Blake Archive,
given its emphasis on quality reproductions, has, since its inception, thought
long and hard about category 1, and now for its redesign, has shifted its
attention to 2 and 3, particularly 2. As it will soon become clear, though, the
problem of representing relationships amongst digital objects goes hand-in-hand
with representing relationships between digital objects and the users
interacting with them. However, the latter is not necessarily a computer-related
issue; these kinds of relationships are not encoded but made implicit, and they
drive a software architect’s modeling of relationships between objects as much
as the nature of the objects themselves do.
Insofar as relationships are concerned, the Blake Archive presents a unique case,
since it is one of the only digital archives that has been in existence for
decades and that is now having to
reconsider its original
configuration of relationships, and thus the effects that any new representation
will incur. And to make matters even more uniquely complicated, as a multimedia
artist and poet, Blake imposes upon digital archivists a multitude of
relationships between objects that is fraught with unusual editorial challenges.
A user of the Blake Archive may discover, for example, that Blake’s bestialized
image of Nebuchadnezzar crawling on all fours is found in both the
Marriage of Heaven and Hell (Figure 1) and Blake’s
series of large color printed drawings (Figure 2).
Some of these relations are currently listed at the bottom of the information
page for every work of Blake’s; users visiting the info page for the
Marriage — to stay on the previous example — can find
the three versions of the
Nebuchadnezzar color
print linkable at the bottom of the page along with other drawings that the
editors have identified as related to various designs among the
Marriage’s twenty-seven plates.
But exactly how are these works related to the
Marriage? And how is a user new to Blake able to know which
particular plate of the
Marriage (24) is the one
related to
Nebuchadnezzar, since there is no information
pertaining to that relationship on plate 24’s object view page (or OVP — the
page that visualizes and provides editorial information for individual plates)
for any of the Archive’s copies of the work? These are among the many questions
concerning relatedness that the staff at the Archive hope to address as we
redesign the site, twenty years after its first digital publication. We shall
return to these questions below and discuss how we are working to clarify and
make easily navigable the types of relationships — both visual and textual —
across the Archive, but first we will list the other ways in which relatedness
is currently identified. As we have grown to encompass more and more of Blake’s
work in various media, the problem of relatedness has grown as well, forcing us
to acknowledge that our current methods of addressing it are insufficient. In a
recent article, Ashley Reed, the Archive’s former and longest-serving project
manager, touched on some of the problems plaguing our handling of relatedness as
the Archive grew — and continues to grow — beyond illuminated books:
[W]hen Archive staff began building a tool that would
actually link related works within the Archive (rather than just listing
them for users to seek out on their own), we began to question this
bibliographic definition of “relatedness” and its
epistemological implications for our project. Were Blake’s watercolor
illustrations to Milton’s Comus,
commissioned by Joseph Thomas in 1801, “related” to
the designs for Paradise Regained,
completed no earlier than 1816, by virtue of anything other than
Milton’s authorship? And if “texts by the same
author” was a valid definition of
“relatedness” for the Archive’s purposes, then
was every one of Blake’s illustrations of the Bible
“related” to every other one — with God
understood as “author”?
[Reed 2014, ¶13]
During Ashley’s tenure as project manager, efforts to address such questions
hewed close to the Archive’s “original vision of
Blake-as-craftsman” — thus, relatedness should be confined to the
material plane. But, as we discuss below, in what we envision as a continued
exploration of challenges concerning relatedness that Reed raised in her
article, despite our best attempts to disambiguate relatedness as the number and
type of Blakean objects published in Archive increased, the need to further
reconsider the epistemological implications of relatedness became clear,
especially as we are venturing into restructuring our data on a relational
model. C. M. Sperberg-McQueen writes that “for computer
applications in the humanities classification most often involves either the
application of pre-existing classification schemes to, or the ‘post
hoc’ identification of clusters among a sample of, for
example, texts”
[
Sperberg-McQueen 2004, ¶4]. Our classification of relations is
decidedly “post hoc”, and the difficulty increases given that
our sample involves both texts and images. We suspect that our struggles will be
recognizable to other digital projects confronting the same issues, and we hope
that our redesigned site might offer one solution to handling the tricky issue
of relatedness in digital archives.
The Archive was originally designed to accommodate digital editions of various
copies of Blake’s illuminated books, to which the first six years of
publications attest.
[1] Since a work like the
Marriage
does not exist as an abstract, Platonic ideal, but is only physically manifested
in the twelve extant copies that Blake printed between 1790 and his death in
1827 (three of which consist of only three or four of the twenty-seven total
plates),
[2] the
relationship between the various prints — each drawn from the same relief-etched
copper plate but varying in coloring and in some instances in text and design as
well — was the first and most obvious type of relationship confronted by the
Archive’s early designers. As such, it is the type of relationship most deftly
handled on the site. On every OVP for illuminated book plates/objects — the
individual Blakean object being the fundamental unit around which the Archive is
constructed
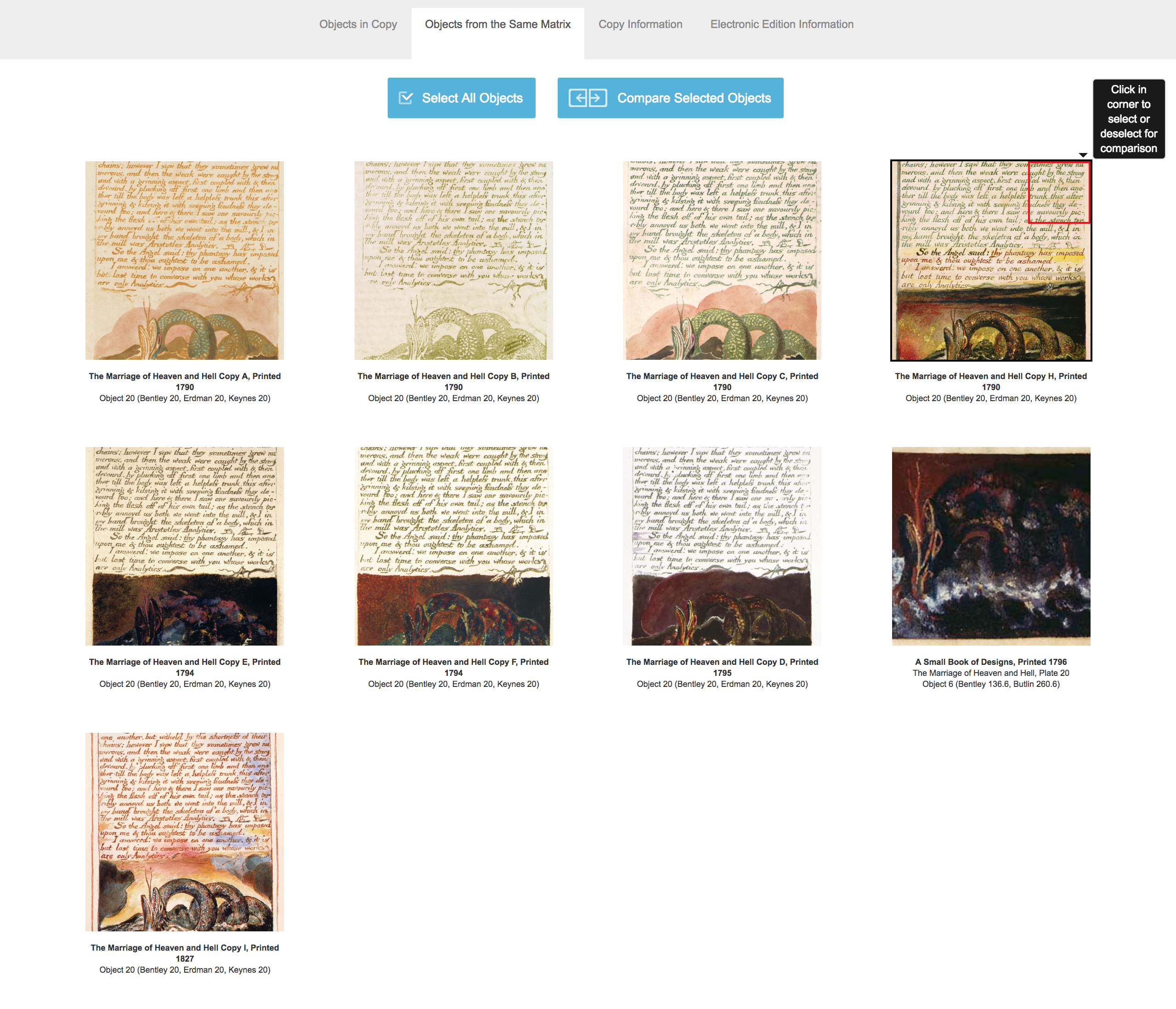
[3] — users have the option of using the
“compare” feature: beneath the image of the object is a
box listing other copies containing the same object, despite that object
potentially being ordered in a different place in different copies; users can
select which copies they wish to compare, the pertinent objects for which are
then arrayed horizontally — and made linkable — in a pop-up window (Figure 4).
Users can easily compare and contrast objects in different copies that Blake
printed from the same copper plate, or matrix. This saves one the trouble of
having to shuttle between the Bodleian Library in Oxford and the Morgan Library
in New York in order to determine the similarities and differences between
plates of copies B and C of the Marriage, for
instance. And as the Archive grew to accommodate non-illuminated book works, the
compare feature still proved useful for any work that featured multiple copies,
such as the two copies of Blake’s illustrations to John Gabriel Stedman’s Narrative, of a Five Years’ Expedition, against the Revolted
Negroes of Surinam.
But this relationship via shared matrix is only one of the many types of
relationships to be found in Blake’s work. The Archive soon began to publish
works that were part of what the editors called the “same
production sequence”, meaning that the works are related by virtue of
being prepared for a specific production. For instance a draft of the
Song of Innocence, “Holy
Thursday”, appears in Blake’s early manuscript,
An Island in the Moon (obj. 14); another well-known example is the
“Death’s Door” design, which appears as both a
water color and engraved illustration for Robert Blair’s
The Grave, as well as the separately printed white-line etching
that scandalized Blake’s patron, Robert Cromek.
Another example of works from the same production sequence that the Archive
recently published are Blake’s preliminary pencil sketches, wash drawings, and
water colors for the
Grave illustrations. All of
these relationships, however, cannot be seen using the Archive’s compare
feature; instead, users need to select “Related Works in the
Archive” from the dropdown “Show Me” menu
in the lower left corner of the OVP.
Titles and links to the related works then appear in a pop-up window, though the
images themselves are not arrayed horizontally, as they are with the compare
feature. No doubt there is value for users in being able to see such related
objects, but it takes a particularly knowledgeable or determined user to
navigate the evasive trail between them.
[4]
Other forms of relatedness began to manifest themselves as well, such as repeated
text and designs in works that are neither printed from the same matrix nor part
of the same production sequence, like the top half of the “Deaths Door” design that can be found on plate 8 of
America a Prophecy.
Such relations were not indicated on the dropdown menu of the OVP for each
object, but were rather added to the “All Known Related
Drawings” lists on the work information pages; but, as noted above,
works in these lists are not all drawings, nor is there explanation or
classification of the various types of relations being compiled.
[5] The information here was painstakingly
gathered and is no doubt of value to Blake scholars, but as these lists grew and
became catch-alls for various types of relationships, the need for revision
became more pressing. And other questions arose: at what point does the
“same” design become a “similar”
design, and hence not worthy of the Archive’s deeming it relational? Is the
bound figure in Blake’s illustration “The Execution of
Breaking on the Rack” for Stedman’s
Narrative (Figure 8) worthy of being conceived as the
“same” design as the bound figure in
America plate 3 (Figure 9)?
The latter is listed on the work information of Blake’s illustrations for
Stedman’s Narrative, but upon reconsideration, the
editors concluded that although intriguing parallels can be made between the two
similar images, they are not a relational instance of the same design, and thus
the redesigned site need not include these objects as related. Additionally,
should Visions of the Daughters of Albion, because
it was composed shortly after the Narrative and is
indebted to Stedman’s attitudes toward slavery and colonialism, be listed as a
related work? And if so, why isn’t the reverse relationship indicated — why
aren’t the illustrations to Stedman’s Narrative
listed as being related to Visions? Such instances
seemed to suggest that the editors were venturing beyond the parameters of
material relations as originally envisioned. Listing all thematic relationships
was a step toward the unhelpful terminus of declaring all objects in the Archive
related because they were all created by Blake.
As for the problem of similar — but not identical — images and texts, the
Archive’s search functionality is designed to handle such cases, and it is being
redesigned to handle them more efficiently. A large portion of the labor
invested into the Archive over the years involves the textual transcription and
image markup, according to carefully designed protocols, of every Blakean
object, in order to render them searchable by text. Users can employ the vast
taxonomy of built-in search terms
to query the Archive for all instances of angels, for example, or for
all designs featuring a male figure lying bound with arms and legs spread; among
the results for the latter example will be
America
plate 8 and object 14 of the Stedman illustrations mentioned above — similar
designs, but not the same design. On the new site, a robust search platform,
Solr, will allow users to discover relations on their own, rather than relying
on the Archive to present every conceivable relational instance. We recognize
that the Archive, despite its aspirations to objectivity, is still, unavoidably,
a mediating interface between Blake and the user, but we try to minimize the
effect of that mediation; we present hard-coded relationships within the Blakean
universe that we deem to be material, but we do not limit a user’s power to see
other relationships, namely interpretable relationships. Even if we were to
implement algorithms for generating relationships, a user, with the powerful
search engine we are designing, will still have the freedom to ignore those
relationships and discover others for himself or herself. And an improved
Virtual Lightbox, the basic image editor provided with the site, will, like this
search engine, allow users to explore and analyze potential relationships
between Blakean objects in a digital space separate from — and thus not dictated
by — the Archive.
[6]As Reed articulates it, while the editorially determined
categories of relatedness are, as such, inherently biased, the search and
Lightbox functions allow for “user-generated
connections” that are “not bound by the Archive’s own standards for
relatedness, but are left to the user’s discretion”
[
Reed 2014, ¶16].
Given the problems detailed above, the redesigned site is being developed to
present Blakean relationships in a more systematic manner. After lengthy email
discussions on blake-proj, our staff listserv, we have come up with relational
categories that will be explicitly differentiated on the redesigned site. In
terms of images, we have opted to designate three levels of relatedness:
- objects printed from the same matrix (equivalent to the “compare”
function on the current site);
- objects from the same production sequence (equivalent to “Related
works in the Archive”); and
- objects with the same design, title, or subject.
The last category could certainly be subdivided, but we are using it to
cover all remaining instances of relatedness that fall outside the first two
categories and that could not be discovered via the search
function.
[7] On the new OVPs, pertinent
relationships will be indicated by tabs directly beneath the images (Figure 11),
objects to which the user can scroll on the same webpage (Figure 12).
All of these categories address object-object relationships that have a
material or textual basis. To the extent that it’s possible, we have tried to
limit the relationships we identify to exclude interpretive ambiguity.
Textual relations require their own categories, and we are currently discussing
how best to classify them. The search function is certainly helpful if the user
already knows what text she is searching for, but we feel that indicating
pertinent textual relations on the OVP — also indicated in tabs below the image
— would also be beneficial. But a preliminary list of various types of Blakean
textual relations, generated by the Archive staff at the University of Rochester
who handle Blake’s manuscripts and typographic works, reveals how quickly such
taxonomic efforts can become complicated.
[8] The list includes categories that involve early drafts of
finished works (like the version of “Holy Thursday” that first appears in
Island and the Moon and later becomes a song of
Innocence), repeating lines in disparate works, descriptions of and references
to visual works in the
Descriptive Catalogue and
letters, texts that fall into the same special group (like those listed in the
Descriptive Catalogue), texts that comment on,
react to, or annotate other texts (such as the “Motto to the
Songs of Innocence & of Experience” in the
Notebook), and more.
But two larger textual categories can accommodate all of these instances:
text-text relationships, and text-image relationships. Although only the
relevant relational tabs will appear beneath the object image on the OVP, we
could nest the particular species of textual relationships within either of
these two genus tabs in order to avoid cluttering the OVP.
[9] But of course a major objective for the redesign is
to no longer hide the types of relationships that we have made accessible in the
database. Here we are navigating the fine line between being transparent with
the types of relationships we are encoding and presenting, and not overwhelming
the user with too much information on the OVP. As Morris Eaves wrote in one of
the many emails addressing this topic, “What began as a
pretty simple matter of reference and utility (it’s handy to know that there
are preliminary drawings of the engravings that Blake produced in
illustrating Wollstonecraft; that there are multiple related versions of the
Job designs and some of the illustrations to Milton; etc.) can pretty easily
become an almost metaphysical matter. I think we all want, and should want,
to resist that”
[
Eaves 2015]. It is difficult to keep matters simple when editing
Blake, and as it turns out, trying to do so has forced us to at least consider
the metaphysical nature of relationality, since we are now shifting to a
relational database, which will serve as the ontological foundation for the
Archive.
“Mechanical Excellence is the Only Vehicle of
Genius”: Implementation
Current Architecture of Relations
In order to understand the values of the new method of representing relations
in the back end, one should understand the current method and its
limitations. We make relations explicit through three types of
documents:
Document Types
- BADs (Blake Archive Document)s
- Work information pages
- Virtual group files
The BAD, an XML document, is the main data document in the Archive. Each one
contains contextual information for a particular copy of a particular work,
such as The Marriage of Heaven and Hell Copy G.
A work information page, also an XML document, contains contextual
information common to every copy of a particular ideal work, like The Marriage of Heaven and Hell. And a virtual
group XML document puts together a set of works that are related in some
special but concrete way of which Blake himself never conceived. For
example, the set of all of his water colors illustrating the bible.
The current site runs on a non-relational database called eXist, which
requires XQuery, a functional programming language, to access. Our eXist
instance holds all of our XML data, which includes the three types of
documents relevant to this matter of relation: to repeat, they are our BADs,
our work information pages, and our virtual groups. Each one handles
relations differently in terms of encoding the relations and relying on
functional code to complete the programmatic representations of the
relations.
Most relations run across the BADs. We say “across” since one BAD contains
information for only one work, which may have one or more objects associated
with it. This means that a representation of a relation is only
half-complete in a single BAD. An XML element or attribute for one object in
one BAD encodes the ID of a related object in another BAD. Non-intuitive
XQuery code provides the connective tissue.
Our work information pages consist of lists, among other things, of “All Known Related Works”,which, as we’ve said,
contain a mix of various types of relations. No connective tissue is
required for these, but they are not encoded, in the sense that they are
simply given under the heading in plain English, “All Known Related Works”. Un-encoded, they are a
challenge to display in more than one way and alongside encoded relations.
The relations made explicit in our virtual groups require no connective
tissue, either. And they are encoded but exist in a sort of
virtual state; that is, they are relations only by virtue of their
constituent members being next to each other in one file and isolated from
other virtual groups.
To recap, we show no textual relations in the current code but four types of
object-object relations:
Relation Types
- Objects Printed From the Same Matrix
- Objects From the Same Production Sequence
- Objects with the Same Design, Title, or Subject
- Objects that Fall into an Editor-defined Virtual Group
The following table illustrates in what document each type of relation is
handled:
| Document Type |
Relation Type |
| 1 (BADs) |
1, 2 (Objects Printed from the Same Matrix, Objects From the
Same Production Sequence) |
| 2 (Work Info Pages) |
3 (Objects with the Same Design, Title, or Subject) |
| 3 (Virtual Groups) |
4 (Objects that Fall Into an Editor-Defined Virtual
Group) |
And below are explanations of examples of each document type handling each
relation type, followed by their corresponding XML and object images:
Document Type 1 (BAD) Handling Relation Type 1 (Objects Printed From
the Same Matrix)In the segment of a BAD below, the value of
the
@compwith attribute of the element
<desc> is the object
ID of an object related by type 1 to the object of object ID
mhh.g.illbk.11. The latter object is object 11 contained in
this BAD for
The Marriage of Heaven and Hell
Copy G. The former object, with its reciprocal
@compwith
attribute, is object 2 contained in another BAD for another work,
A Small Book of Designs, the ID of which begins
with the string “bb136”. An XQuery expression in
the code makes the connection.
BAD filename: mhh.g.xml
<desc id="mhh.g.illbk.11" dbi="mhh.G.P11" compwith="bb136.B2">
Document Type 1 (BAD) Handling Relation Type 2 (Objects From the Same
Production Sequence) In the following code snippet from a
BAD, the
<related> elements indicate object IDs of objects related by
type 2 to the object of ID but146.1.wc.01, the only object of the work
“Enoch Walked with God.” Again, an XQuery expression in the code makes the
multiple connections to complete the representations of the relations. One
can imagine reciprocal
<related> elements for each of the related
objects contained in their own BADs.
BAD filename: BUT146.1.xml
<desc id="but146.1.wc.01" dbi="BUT146.1.1.WC">
<relatedobjectid="but550.1.wc.02"/>
<related objectid="but551.1.wc.02"/>
<related objectid="but557.1.penc.08"/>
<related objectid="bb421.1.spb.04"/>
</desc>
Document Type 2 (Work Info Page) Handling Relation Type 3
(Objects With the Same Design, Title, or Subject)
In the following snippet from a work information page, a relation of type 3
is indicated. All of the objects, in this case one object, in the work of ID
esxiii,
Deaths Door, are shown to be related to
The Marriage of Heaven and Hell plate 21.
This work information page, beyond the snippet below, contains multiple
<relationship> elements, indicating further objects relating to
Deaths Door. As XML elements, they are
technically encoded, but their kind is not precisely distinguished like the
relation types of the previous two examples. As such they don’t lend
themselves to a better exhibition than a textual listing. And the object IDs
of all the related objects are not immediately apparent. To form the link to
a related object that is actually in the Archive, an XQuery expression must
read the
<link> attributes, string them together, and find the
resulting ID in the pool of BADs in the eXist database.
Work info page filename: esxiii.info.xml
<related>
<relationship>
<link type="compare" ptr="mhh.c" objnum="B21">
<i>The Marriage of Heaven and Hell</i>, plate 21</link>
<br/>
Relief and white-line etching, 1790. Bentley 98, plate 21.
</relationship>
</related>
Document Type 3 (Virtual Group) Handling Relation Type 4 (Objects
That Fall Into an Editor-Defined Virtual Group) The
following snippet shows part of a virtual group defined by the editors as
Water Color Drawings Illustrating the
Bible. Works, in this case single-object works, are grouped
together by their IDs using
<include> elements. Virtual groups can be
thought of as editor-defined ideal works with multiple objects; they are the
most interpretive of the sets of relations in the Archive.
Virtual group filename: biblicalwc.xml
<vgroup name="Water Color Drawings Illustrating the Bible" id="biblicalwc">
<include bad="but146.1" header="Old Testament Subjects"/>
<include bad="but435.1"/>
<include bad="but436.1"/>
<include bad="but438.1"/>
</vgroup>
New Architecture of Relations
Is the current method of representing relations convoluted? Absolutely. Not
conducive to change? Not admissive of further types of relation? Yes, yes,
hence the dire need for simplification.
With PostgreSQL, an open-source relational database, in the new architecture,
all of our explicit representations of relations have been extracted and
consolidated into one large table, which may be accessed by basic SQL
statements. The first column of the table lists in its rows every object ID
in the Archive, over 3000 and counting. Every succeeding column represents a
different type of relation, and the fields of the table are filled in
appropriately with object IDs. So the single table shows how every object
relates to every other. To pull out a relation, a simple SQL command
suffices. No connective tissue is necessary. The relations are encoded. And
an editor can easily introduce another relation or relation type into the
mix simply by adding an object ID to a field or by inserting a new column,
respectively. As Stephen Ramsay says, in the context of humanistic study, a
relational database is a “para-interpretive formation”
[
Ramsay 2004, ¶4]. It yields to the scholar’s will. Here is how a couple of rows from
the table might look:
[10]
| object ID |
related object ID(s) by type 1 |
by type 2 |
by type 3 |
by type 4 |
| 1 |
5,6,3,2 |
|
7,8 |
|
| 2 |
1 |
9 |
|
25 |
The process of creating this PostgreSQL table required us first to parse our
XML documents with a PHP XML parser to isolate and pull out the relevant
values of the elements and attributes for the first two types of
relationship, objects printed from the same matrix and objects from the same
production sequence. We then appropriately inserted these values into a
temporary Excel spreadsheet to be verified and validated, to borrow terms
from computer science.
Verification in computer science is the process of checking whether the
software satisfies the specification. Validation is the process of checking
whether the specification of software meets the customer’s expectations.
Translated to the science of digital editing, in this case, verification was
the process of checking whether the relations pulled out were
“correct”, and validation was the process of checking
whether the set of relations pulled out for each type was
“complete”. Each of the two sets was determined to be
complete if it contained all of its expected relations between works in the
Archive, not in Blake’s entire oeuvre since the Archive doesn’t have all of
Blake’s works. We are thankful for having had diligent editorial assistants
and knowledgeable editors to help.
Making another spreadsheet for the third type of relation, objects with the
same design, title, or subject was even more tedious because, as noted, the
third type is handled by our work information pages, which don’t actually
encode the relations they express. We had to painstakingly go through each
listed relation, given in plain English and already verified and validated,
find the object ID or IDs associated with the relation, and manually type
them into the spreadsheet. It was during this process that the staff had the
most conversation about what relations in the Archive should be explicitly
distinguished. In the end we decided to keep these relations lumped together
under the very inclusive third type: objects with the same design, title, or
subject. Part of the reason for our decision was because our lists of “All Known Related Works” contain some works
currently not in the Archive.
Creating a third spreadsheet of relations for the fourth type was more
straightforward. First, we assigned each virtual group a unique id. Then, we
used a PHP script to collect the object IDs for each BAD ID in each virtual
group and labeled them according to their corresponding virtual group IDs in
the spreadsheet.
Now we had three spreadsheets of relations, of which the first columns
consisted of object IDs. We imported the spreadsheets into PostgreSQL tables
and joined them on their object IDs into one table. A
“join” operation combines the information from
multiple tables, based on a common field between them, in this case the
object id. We then merged rows with the same object IDs and made the table
commutative. The commutative property in this case holds that if object X
relates in some way to object Y in the table, then object Y must be shown to
relate in the same way to object X. The malleable table may take on
non-commutative relations in the future if we find that such relations exist
between Blake’s works and decide to exhibit them in the Archive.
The beauty of the table is that it is readable to editors and at the same
time programmatically efficient. An editor can refer to it, augment it, and
adjust it like the index of a book, and a programmer may access its
represented relations with simple SQL statements rather than convoluted
XQuery code unique to each type of relation. In Blake’s terms, the table is
a single composition of thousands of minute particulars.
[11]Once we are done classifying textual relations we will encode them
appropriately in the table. We are currently using a C++ program called
Superfastmatch to programmatically discover the textual matches across all
of Blake’s works and between his works and other works he is known to have
referenced like Milton’s poetry and the King James Bible.
[12]
Superfastmatch is the open-source bulk document comparison technology behind
churnalism.com, a website
built by Media Standards Trust used to distinguish original journalism from
regurgitated journalism. We encourage the use of Superfastmatch in digital
humanities endeavors similar to ours.
As we redesign our site, we are also developing a prototype making use of
Superfastmatch in conjunction with our editor-defined relations as a
relation suggester: if object A relates by type X to object B and object B
is shown by Superfastmatch to contain a textual match with object C, then
the tool will suggest to the scholar that object A and object C might be
related in some way yet to be defined, that a loose transitive property
might hold for the relationships amongst these objects. ‘Might’ is the
keyword here. The scholar may use his or her own discretion in deciding upon
the validity of the suggested relation and the nature of it. Such a
human-in-the-loop algorithm directs the discerning critic’s attention but
respects his or her own sensibility and expertise. A computer is an enabling
technology, not a replacement for human perception.
We are also developing a prototype employing Superfastmatch together with the
collation tool Juxta, which finds differences between documents, not
similarities.
[13] This
tool will allow a user to select two or more object transcriptions in the
Archive and see their similarities and differences at the same time in a
user-friendly environment constituting yet another instance of coincidence
of opposites in the world of Blake. We imagine it in production to be a fine
addition to our image comparison feature, enriching the Archive’s web of
relations even more.
“My fingers Emit sparks of fire with Expectation of my
future labours”: Anticipation
The difficult task of presenting more kinds of relationships in the Archive has
compelled us to reevaluate Blake’s methods and reencode the connections between
his works accordingly. As we have shown, we have had to set new specifications
and engineer a new implementation for this part of the Archive, all while doing
the same for the back and front ends of the rest of the site. And at the moment
of this writing, the redesign is still in progress. We anticipate the need to
address unforeseen questions and challenges as we further define and implement
textual relationships, and as we continue to refine the interface to most
clearly display the various types of relations we have identified. A clearer and
more systematic handling of the complex relations among Blake’s art is just one
of the many improvements that a redesigned Blake Archive will offer.
But the process of achieving these improvements does not have to benefit only the
Blake Archive and Blake scholars. We hope that editors of other established
digital archives, especially those archives in need of upgrades and with
potential for exhibiting further relationships between their items, would learn
from our practices. Particularly relevant here is our commitment to move from an
XML query engine to a combination of the relational database, PostgreSQL, and
the robust search engine, Solr. When we debated this transition and sought
advice from other digital humanists, the responses we received were far from
unanimous, yet all expressed strong conviction in their particular opinion. In
the end, we opted to keep our data (BADs and info pages) in XML, not to abandon
XML altogether, which many whom we solicited advised. Leaving our BADs intact is
reassuring to the editors who have invested decades in creating them and who are
familiar with their structure. But the addition of the table of relationships
between every object in the Archive offers a more efficient and intuitive way to
harness this aspect of our data. And typing the table into existence, we imagine
this notion of archival relationship exploding into one
“amongst” archives not just “within”
them, and we invite collaboration in this regard.
We also intend to do a further study on the philosophical context of Blake’s
practice of making related works of art, and on the philosophical context of our
practice of archiving these related works.
Blake emphasized through his aesthetic the independent nature of the “Singular & Particular”, which he claimed to be the
foundation of the sublime (E 647). Yet, as we have shown, Blake wanted his
audience to see parallels between the objects of his works. In this way, he was
more in line with Locke and Locke’s followers than one might expect, given his
well-known critical stance against them. Being able to relate discrete ideas, or
perceptions, was for these contemporaries of Blake foundational to higher levels
of abstraction. While classical metaphysics divided the world into substance,
mode, and relations, prioritizing the first,
[14] Locke’s
Essay Concerning
Human Understanding made relations most fundamental to his
epistemology. Knowledge itself he defined as “the perception
of the connexion and agreement” between ideas; when two discrete
ideas agree, they bear a likeness to each other; they involve a relation [
Locke 1975, 4.1.2, 525]. Exactly what allowed the mind to
connect related ideas remains a mystery in Locke’s theory, but nevertheless, the
ability of the mind to do so played a crucial role in the associative
psychologies of Hume, Hartley, and Priestley later in the eighteenth century,
all of whom acknowledged their debt to Locke.
The concept of relatedness in the context of archival practice may be
historically situated in terms of 16th-century types of similitude, particularly
“analogy”, the third of four that Foucault discusses in
“The Prose of the World”. Like the first,
“convenientia”, “analogy” is conceived
in terms of connections or bonds, and like the second,
“aemulatio,” it disregards distance in space. But it
threatens to proliferate out of control, unlike the others, because it is not
limited to the substantial; it admits subtle and abstract resemblances, the
invisible [
Foucault 2002, 24].
Analogy was reflected by negation in the idea of the cabinet of
curiosities, a kind of collection, originating in the Renaissance, that
contained objects whose analogical relations were not rigidly defined. Each
object related to every other by virtue of being grouped together and falling
under categories that bled into each other. Such a world precludes a spectrum of
meaningfulness amongst relations. To prevent an archive from being a cabinet of
curiosities, the archivist must delimit analogical relations between its
objects. As Foucault says, “man is the fulcrum upon which
all these relations turn”
[
Foucault 2002, 25]. The digital archivist, in particular,
must also set the boundaries of the relations into a kind of spatial map
conducive to computation. He must “encode” the relations
because he caters not just to people but also to machine. The relations he
brings into being have to be accessible to the mind as well as the code. This
new type of similitude, analogy that is not “freed from the
law of place”, we may call grounded analogy [
Foucault 2002, 21]. It is one thing that separates nature
from machine, and we’ve kept it constantly in sight while redesigning the front
and back ends of the William Blake Archive.