


Volume 14 Number 2
Curadoria Digital e Custos – Exploração de abordagens e perceções
Digital Curation and its Costs: A Study of Practices and Insights
Abstract
Introdução – No âmbito das preocupações que estão na origem da curadoria digital, toma-se como exemplo o contexto da produção de grandes volumes de informação científica, que requer abordagens que garantam a sua manutenção, reutilização e valorização, dado o seu elevado custo.
Objetivos – Pretende-se conhecer o pensamento existente referente aos custos da curadoria digital e desenvolver uma proposta de modelo de enquadramento para a análise de custos em curadoria digital, inclusivamente projetos de carácter mais prático. Tal implica abordar a definição deste conceito e a problemática dos custos, baseando-nos nos estudos referentes a modelos de custos.
Metodologia - Procedeu-se a uma revisão da literatura, contextualizando a questão dos custos no seio da curadoria digital, delimitada pelos dados recolhidos nas fontes de pesquisa, a Biblioteca do Conhecimento Online (B-On) e o Repositórios Científicos de Acesso Aberto de Portugal (RCAAP). Em seguida, desenvolveu-se um modelo de enquadramento esquematizado com base nas categorias identificadas por via do Método da Comparação Constante, algumas relacionadas com o Modelo de Referência Open Archival Information System (OAIS) e o ciclo de vida Digital Curation Centre (DCC). Tal permitiu desenvolver uma análise de conteúdo das perceções recolhidas em diversos autores, resultando em memorandos, de que este texto é um resumo.
Resultados/Conclusão – Propõe-se um esquema de sistematização das problemáticas da curadoria digital, que constitui um modelo de enquadramento que se considera pertinente para a análise de custos em curadoria digital, inclusivamente projetos de carácter mais prático, e que interliga a visão do ciclo de vida da curadoria do objeto digital do DCC e a abordagem do modelo de referência OAIS, numa lógica transversal apreendida pelos Modelos de Custos e Plano/Políticas de gestão dos dados. Conclui-se que se deteta uma mudança de paradigma, de uma visão de black-box para uma abordagem de identificação dos custos e de tentativa de sistematização de modelos de previsão para utilização institucional, como forma de incentivar a transparência e a accountability e de captar o interesse de potenciais financiadores.
Introdução
A pesquisa (metodologia e dados)
A Curadoria digital e os Custos: O Desenvolvimento do Modelo de Enquadramento de Análise
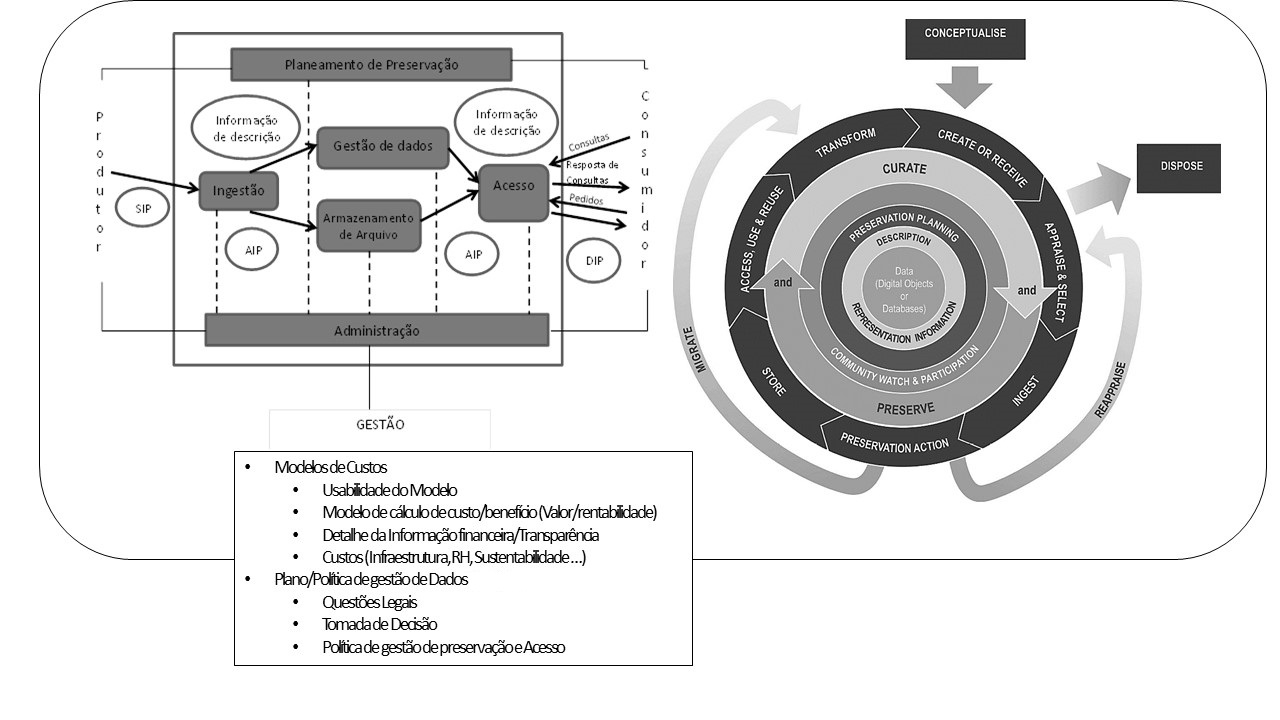
A curadoria digital e os Custos na perspetiva dos estudos: Exemplo da Aplicação do Modelo de Enquadramento de Análise
Conclusão
Apêndice
| Origem da Categoria | Designação da Categoria |
| OAIS e o Ciclo de Vida DCC | Produção de dados |
| Ciclo de Vida DCC | Avaliação e Seleção |
| OAIS e o Ciclo de Vida DCC | Ingestão |
| OAIS e o Ciclo de Vida DCC | Preservação (Digital) |
| OAIS e o Ciclo de Vida DCC | Armazenamento |
| OAIS e o Ciclo de Vida DCC | Acesso, uso e reutilização |
| OAIS | Disseminação/divulgação |
| OAIS | Administração |
| Modelo do ciclo de vida DCC & Modelo de referência OAIS | Modelo do ciclo de vida DCC & Modelo de referência OAIS |
| Análise própria | Modelos de custo |
| Análise própria | Usabilidade do Modelo |
| Análise própria | Modelo de cálculo de custo/benefício |
| Análise própria | Valor/rentabilidade |
| Análise própria | Detalhe da informação Financeira do Modelo/transparência |
| Análise própria | Custos |
| Análise própria | Infraestrutura |
| Análise própria | Sustentabilidade |
| Análise própria | Plano/Política de gestão de Dados |
| Análise própria | Questões legais |
| Análise própria | Tomada de decisão |
| Análise própria | Política de gestão de preservação e acesso |
| Designação da Categoria | Autores | Comentários e ideias expressas pelos autores |
| Produção de dados | Bicarregui et al. (2013) e Santos (2014) | Referem-se aos custos da investigação científica na Big Science, que lida com volumes de dados dificilmente esgotáveis em artigos publicados, apresentando problemas de gestão, que são qualitativamente diferentes de outras disciplinas, daí serem inevitavelmente projetos de larga escala, familiarizados com estimativas de custos. |
| Lee et al. (2016) | Detetam que muitos planos ainda falham na abordagem aos custos relacionados com a criação de dados abertos. | |
| Avaliação e Seleção | Poole (2015) | Defende que se considerer o custo dos materiais, o tipo, o estado, a quantidade, a acessibilidade e a singularidade, e possibilidades de uso futuro |
| Ingestão | Dürr et al. (2008) | Referem a importância do controlo de qualidade. |
| Preservação (Digital) | Ayris (2009) | Aponta para a necessidade de um modelo genérico para identificar elementos-chave das atividades de preservação, fatores que contribuíram para as despesas, para identificação e redução de momentos de concentração de custo e a periodicidade dessas ações. |
| Kejser et al. (2011) | Defendem que os custos de preservação são custos recorrentes, dependentes da gama de serviços que uma instituição oferece, sendo difícil separá-los dos outros custos de ciclo de vida. | |
| Bicarregui, et al. (2013) | Mencionam que muitos dos custos de curadoria vêm da preservação, pelo que da sua boa gestão depende o desaparecimento de um conjunto significativo de problemas práticos relativos ao desbloqueamento de dados. Dentro de esta fase, incluem-se as estratégias de migração e emulação. | |
| Armazenamento | Wright et al. (2009) e Santos (2014) | Identificam que a constante queda do preço destes dispositivos promove a utilização de maior espaço de armazenamento, mas os custos de energia, espaço, refrigeração e gestão são crescentes. |
| Whyte & Pryor (2011) | Integram-nos nos custos de reutilização encarados por um repositório. | |
| Rice et al. (2013) | Advogam que o armazenamento deve cumprir normas abertas, ter escalabilidade e permitir utilizar hardware de vários vendedores, com mecanismos de acesso de dados flexíveis. | |
| Rosenthal & Vargas (2013), Suchodoletz et al. (2013) e Saraiva & Quaresma (2015) | Contrapõem o armazenamento local com serviços de computação em nuvem para preservação partilhada. | |
| Acesso, uso e reutilização | Rusbridge & Ross (2007), Queiroz (2013) e Machado (2015) | Concluem que o aumento dos custos das assinaturas de jornais científicos serviu de incentivo ao surgimento do movimento de acesso aberto. |
| Whyte & Pryor (2011) e Saraiva & Quaresma (2015) | Referem que o acesso livre aos dados científicos (Open Science) traz poupanças na aquisição, no acesso e na gestão, e menos barreiras à participação e à colaboração ativa de pessoas de fora numa comunidade científica. | |
| Lee et al. (2016) | Referem que a lógica que parece estar por detrás da obrigação de disponibilizar gratuitamente os dados da investigação científica financiada publicamente, refere-se ao retorno feito à Sociedade do investimento feito com os dinheiros públicos. | |
| Bicarregui et al. (2013) | Defendem a preponderância da questão dos dados abertos relativamente à preservação, assim como a necessidade de selecionar os dados a preservar. | |
| Evans & Moore (2014) e Poole (2015) | Realçam o papel da partilha e da reutilização de dados na diminuição de custos face à produção de novos dados numa época de austeridade económica, tendo o cuidado de permitir a reconstituição em formas e formatos diferentes do original. | |
| Sayão & Sales (2012) | Mencionam que o valor dos dados relaciona-se com reprodutibilidade da pesquisa que o originou para análise de custo-benefício relativa ao acesso e à capacidade de reutilização dos dados. | |
| Dürr et al. (2008) | Apresentam um sistema projetado para garantir a reutilização de dados primários e produzir dados secundários. | |
| Minor et al. (2010) | Apelam para que se assegure a proteção de coleções de dados críticos para além do tempo de vida dos projetos e esforços que os geram. | |
| Whyte & Pryor (2011) | O uso de dados secundários tem consequências para a redução dos custos de colheita e duplicação de dados, a partilha dos custos diretos e indiretos da colheita, e os novos usos não previstos no momento da colheita (ex. Mineração de dados), mas são portadores de custos em termos de armazenamento e preparação de dados para a curadoria e partilha. | |
| Rice et al. (2013), Wilson & Jeffreys (2013), Delasalle (2013) | Compete às instituições de investigação que desenvolvam infraestruturas que suportem a variedade de dados e a sua reutilização, por serem dados de investigação financiada publicamente, sendo este um dos desafios a superação do ceticismo entre os investigadores. | |
| Acesso, uso e reutilização (continuação) | Donnelly & North (2011) | Dfendem que os centros de investigação e prestadores de serviços de informação devem orientar as políticas e as estratégias para as necessidades das comunidades de investigação para otimização da utilização e troca de informação. |
| Bicarregui et al. (2013) | Referem a escolha de produtos de um projeto, que representa para o cientista um compromisso que envolve a quantidade de tempo que pode investir na compreensão desses dados, o grau de apoio que recebe dos colegas e os proprietários de dados, e a subtileza da questão que desejam tratar. | |
| Machado (2015) | Reporta-se aos menores custos de novas investigações desenvolvidas a partir dos dados científicos partilhados. | |
| Whyte & Pryor (2011) | Identificam os dados científicos partilhados com a poupança nos custos indiretos de investigação através da utilização de recursos agrupados (evitando a fadiga da colheita) e a “troca de presentes” disponíveis para acelerar a investigação da ciência derivada, que originaram aumentos da eficiência e trouxeram uma mudança de patamar. | |
| Poole (2015) | Defende que qualquer modelo que defenda a eficiência e a eficácia económica da partilha de dados não espelha a complexidade das relações humanas imbricadas na sua produção. | |
| Akers & Green (2014) | Referem que os benefícios da colaboração incluem o acesso a uma ampla gama de experiências, partilha de custos e recursos, acesso a novas ferramentas, desenvolvimento de normas e boas-práticas e consciencialização para o problema, tendo as bibliotecas académicas um papel de promoção da partilha e da preservação de dados científicos. | |
| Whyte & Pryor (2011) | Baseiam-se nas Diretrizes da OCDE para defender o menor custo de acesso possível, de preferência não superior ao custo marginal de disseminação, indicando que menores custos de acesso aos conhecimentos científicos anteriores dependem do financiamento público dos investigadores para o aceder. | |
| Disseminação/divulgação | Bicarregui et al. (2013) | Argumentam contra a divulgação generalizada de dados, por não ser gratuita e ter custos significativos. |
| Whyte & Pryor (2011) | Concluem que, com a partilha, devem aumentar os custos ligados à compreensão dos dados (preparação e documentação, usando esquemas de metainformação reconhecidos, custos de revisão), em vez de diminuir. | |
| Lee et al. (2016) | Mencionam que vários governos obrigam as instituições de investigação científica financiada por verbas públicas a disponibilizar os dados gratuitamente para acesso público. | |
| Dürr et al. (2008) | Recomendam investigação sobre ferramentas de visualização para pesquisa e recuperação de conjuntos de dados. | |
| Wilson & Jeffreys (2013) | Abordam os custos de divulgação de serviços de gestão de dados. | |
| Lee et al. (2016) | Afirmam que muitos planos ainda falham de forma significativa na abordagem aos custos para garantir a recuperação dos dados. | |
| Administração | Kejser et al. (2011) | Assumem a monitorização como a vigilância da comunidade de interesse (custos variam inversamente consoante a influência da entidade curadora na produção e utilização de formatos) e tecnologia (custos dependem do desenvolvimento e complexidade). |
| Poole (2015) | Refere a necessidade de equilíbrio para que os custos de vigilância proactiva não sejam desproporcionados. | |
| Modelo do ciclo de vida DCC & Modelo de referência OAIS | A generalidade dos autores | Tece comentários sobre estes modelos no âmbito de projetos dedicados aos modelos de custos da gestão e preservação de dados. Refere que a sua simples leitura e implementação, embora aconselhável, não tem um caráter obrigatório na gestão e na preservação de dados, a menos que se considere a validação, a auditoria e a modelagem de custos de acordo com estas especificações. |
| Modelos de custo | Currall et al. (2007) | Compreender e comunicar o custo e o valor das atividades de curadoria são fatores importantes para assegurar a sobrevivência de ativos digitais a longo-prazo, mas existem problemas para exprimir compreensivelmente o seu valor a todas as partes interessadas, especialmente aos potenciais financiadores. |
| Davies et al. (2007) | Concluem que os custos podem surgir em diferentes fases do ciclo de vida, ser recorrentes e com diferentes frequências. | |
| Wright et al. (2009) | Apresentam uma abordagem ao risco, que combina dimensões de custo, incerteza e benefício, considerando os modelos de custo e valor como uma parte da atividade mais ampla da modelação económica, que por sua vez é apenas parte da realização de preservação digital e do acesso sustentáveis. | |
| Ayris (2009) | Efetua diversas recomendações, tais como a necessidade de efetuar o cálculo de custos ajustados à inflação e de considerar os custos externos ao ciclo de vida. | |
| Bicarregui et al. (2013) | Referem que os projetos de modelos de custo não produziram consenso e que tal pode nem ser possível dada a variedade de contextos de preservação. No caso dos dados não acedidos, há ainda menos apoio em termos de modelagem de custos. | |
| Kilbride & Norris (2014) | Defendem que, para garantir que a modelação de custos, esta não se torne um fim em si, tendo de abranger conceitos relacionados como risco, valor, qualidade e sustentabilidade. Afirmam que a investigação da modelação de custos de curadoria tem sido muito ativa, tendendo a valorizar os custos de preservação, pela dificuldade em articular os benefícios da preservação e a complexidade da tarefa. | |
|
Modelos de custo
(continuação)
|
Evans & Moore (2014) | Exemplificam a complexidade da tarefa com o facto de uma decisão aparentemente simples, como formato do ficheiro, ter sérias consequências na preservação e na reutilização. Concluem que, embora os modelos de custos afirmem ser genéricos, tendem na prática a ser específicos de determinadas instituições, ao mesmo tempo que as entidades protegem justamente as informações acerca dos custos considerados sensíveis. Outras lacunas identificadas foram a má usabilidade e a falta de consenso sobre a forma de estruturar os dados de custo. |
| Faria & Ferreira (2012) | Consideram que este domínio evoluiu bastante derivado de uma maior compreensão dos custos e do facto de estes modelos permitirem que os processos de decisão estratégica sejam mais eficientes e precisos, embora não exista um modelo único aplicável a todos os casos. | |
| Usabilidade do Modelo | Kejser et al. (2011) | Defendem que os modelos de custos são imprecisos para estimar o custo futuro devido aos desafios colocados pela manipulação do elemento de previsão, que influencia vários aspetos do modelo. |
| Kilbride & Norris (2014) | Apontam para a pouca absorção das ferramentas e dos métodos desenvolvidos com os modelos de custos. | |
| Modelo de cálculo de custo/benefício | Currall et al. (2007) | Apontam a necessidade de melhor informação sobre custos e benefícios para aperfeiçoar o processo de tomada de decisão por parte dos gestores e investidores. Estes pretendem tomar conhecimento dos potenciais benefícios que a gestão cuidada da informação digital pode trazer para os clientes externos da organização (talvez através de um maior acesso), e se melhorará o desempenho dos processos da instituição, ou se ajudará a desenvolver o seu negócio e a expandir seu conhecimento, assim como a ter noção do impacto que terá sobre as suas finanças, e se o custo das ações necessárias é menor ou maior que o valor de uma coima por não-conformidade. |
| Bicarregui et al. (2013) | Consideram os custos razoavelmente objetivos, e embora seja difícil estimá-los para lá de uma certa ordem de magnitude, podem ser estimados. Em contrapartida, a valorização é, muitas vezes, difusa, envolvendo benefícios educativos e de assistência, que são reais, mas apenas concretizáveis em uma análise formal de custo-benefício. | |
| Kilbride & Norris (2014) | Consideram necessário o fornecimento de modelos de custo-benefício claros, incluindo a sua descrição conceptual e vocabulário normalizado. | |
| Valor/rentabilidade | Currall et al. (2007) | Perspetivam o valor a nível de geração de renda através de venda de ativos, licenciamento e/ou direitos de bens, ensino e de investigação, contratos, subvenções, taxas, doações, e a nível de redução de custos de trabalho, tempo espaço e despesas diretas. |
| Evans & Moore (2014) | Concluem que a avaliação do valor e do impacto dos dados tornaram-se cada vez mais importantes num clima de recessão e de diminuição da atividade económica. | |
| Detalhe da informação Financeira do Modelo/transparência | Kilbride & Norris (2014) | Discutem se os modelos de custo-benefício atuais vão ao encontro das necessidades dos interessados no cálculo e na comparação de informação financeira. |
| Ayris (2009) | Refere a inadequação dos modelos de financiamento a termo (bolsas de investigação ou contratos) de modo a responder às necessidades de acesso e preservação a longo-prazo. | |
| Custos | Wilson & Jeffreys (2013) | Referem que os serviços institucionais têm muitas vezes custos fixos elevados relativamente aos custos variáveis (necessidade de desenvolvimento constante e recursos humanos). |
| Whyte & Pryor (2011) | Defendem que a redução de custos indiretos requer o uso eficiente de recursos escassos na recolha de dados, incluindo temas de investigação e instrumentação. | |
| Lee et al. (2016) | Defendem que a eficiência também poderia ser atingida pela cooperação interinstitucional como forma de reduzir os custos de conformidade. | |
| Kejser et al. (2011) | Defendem a ideia de que os modelos devem representar custos económicos completos, sejam eles diretos ou indiretos. Dentro de estas categorias de custos, os estudos abordam os custos de descrição ligados à metainformação, os custos crescentes de processamento e os custos associados a aquisições em geral e a recursos humanos. | |
| Infraestrutura | Wright et al. (2009) | Referem que os modelos Total Cost of Ownership das instituições são muitas vezes modelados erradamente como um valor anual. Tais custos são substanciais a nível institucional, sendo preciso ter em conta a dimensão do serviço para assegurar que responde às necessidades. |
| Suchodoletz et al. (2013) | Referem a alternativa de usar uma nuvem pública, de modo a que as instituições evitem a manutenção de servidores dispendiosos e subutilizados. | |
| Sustentabilidade | Ayris (2009) |
Identifica um conjunto de elementos-chave para alcançar a sustentabilidade
das coleções digitais a longo-prazo.
Constata, a nível de planos de financiamento, a falta de incentivos para
impor modelos económicos sustentáveis, pelo que o financiamento da curadoria
digital continua a basear-se em projetos de curto prazo.
Defende que, em termos de custos de risco, a incerteza, a imprevisibilidade
e a ameaça de ocorrência podem ser tratadas por planos e orçamentos de
contingência, reservas estratégicas ou seguros para mitigar as perdas.
|
|
Sustentabilidade (continuação)
|
Poole (2015) |
Considera que as instituições tendem a dedicar uma ínfima parte dos seus
orçamentos à curadoria e que o financiamento não acompanha o crescimento dos
dados, pelo que os planos devem demonstrar liderança empresarial, propostas
de valor preciso, minimização de custos e exploração de fontes de receitas
variadas, assim como compromissos mensuráveis para prestação de contas.
A nível de planos de financiamento constata que embora os financiadores
identifiquem os resultados sustentáveis, muitas vezes negligenciam a
definição de os resultados acordados serem alcançados ou medidos.
Afirma que o desenvolvimento de modelos de negócio, bem como a colaboração
através de redes de preservação constituem preocupações cruciais no cálculo
de custos.
A explicitação dos riscos permite o desenvolvimento de uma abordagem que
justapõe risco com custos e benefícios.
|
| Wilson & Jeffreys (2013) | Concluem que os modelos de negócios são melhor produzidos ao nível dos componentes individuais, em vez de em termos de totalidade da infraestrutura. | |
| Suchodoletz et al. (2013) |
Exemplificam a ligação íntima da questão da partilha de custos com o
desenvolvimento de modelos de negócio, e a colaboração através de redes de
preservação no cálculo de custos.
Abordam a questão da utilidade da avaliação do potencial de absorção de um
serviço pelo público, relativamente à capacidade de planeamento e
desenvolvimento do modelo de negócio.
|
|
| Lee et al. (2016) |
Mencionam a partilha de custos pela cooperação interinstitucional para
poupar no investimento feito no âmbito da conformidade legal.
Ainda existem várias instituições de investigação científica que não têm em
consideração os custos nos seus planos para disponibilizar os dados de forma
sustentável.
|
|
| Wright et al. (2009) | Abordam a modelação de custos de risco ligada à incerteza, à imprevisibilidade e à ameaça de ocorrência. | |
| Plano/Política de gestão de dados | Lee et al. (2016) | Indicam que algumas instituições de investigação científica continuam a mencionar de forma breve ou até a silenciar os custos monetários e administrativos nos seus planos. Poucas instituições sugerem que os investigadores deveriam consagrar os custos da gestão de dados nos seus orçamentos. |
| Ayris (2009) | Advoga a escolha da dimensão adequada das atividades de preservação, que precisam de ser suficientemente grandes para conseguirem responder aos desafios, mas não tão grandes que modo a que o seu fracasso possa ser catastrófico. Considera não haver substituto para uma organização flexível, empenhada e dedicada em preservar um corpus de material. Esta organização deve ser capaz de fazer escolhas e traçar estratégias para lidar com problemas inesperados de todo o tipo. Se necessário, pode realizar triagens e estabelecer compromissos. | |
| Donnelly & North (2011) | Observam que a existência de uma abordagem única para o futuro das ciências ou uma política de dados não específica não será produtiva e eficaz, e que as políticas e a prestação de serviços de informação precisam de se aproximar das comunidades de investigação. | |
| Wilson & Jeffreys (2013) | Afirmam que os investigadores não estão expostos aos custos reais das soluções de gestão de dados (frequentemente subaproveitados), ao passo que, quando estes serviços estão centralizados, os custos totais são visíveis e desanimadores. | |
| Delasalle (2013) | Defende que os planos de gestão de dados devem corresponder às expectativas dos cientistas e à sua área de estudo e também servir para calcular os custos associados aos planos do projeto. | |
| Rice et al. (2013) | Consideram que um serviço gratuito no momento da utilização elimina uma das principais barreiras para a boa curadoria e permite que os dados possam ser guardados na infraestrutura adequada, em vez de uma infraestrutura escolhida em função do menor custo. | |
| Questões legais | Poole (2015) | Defende que as suas exigências devem ser equilibradas pelas partes interessadas, no âmbito da política. |
| Bachell & Barr (2014) | Mencionam os direitos de propriedade intelectual em termos de videojogos. | |
| Barros (2014) | Mencionam os direitos de propriedade intelectual em termos de conteúdo jornalístico. | |
| Lee et al. (2016) | Referem a existência de obrigações legais por parte das instituições de investigação científica financiada pelo governo dos EUA, devendo disponibilizar os dados em acesso público gratuito, os quais devem ser detetáveis e utilizáveis. | |
| Tomada de decisão | Whyte & Pryor (2011) | Identificam deliberações para os decisores políticos, investigadores e comunidades de utilizadores sobre os riscos, os custos e os benefícios de uma participação mais ampla antes e depois dos resultados serem produzidos. |
| Delasalle (2013) | Defende o envolvimento dos investigadores no processo de tomada de decisão sobre o que é mantido, onde e por quanto tempo. | |
| Política de gestão de preservação e acesso | Bicarregui et al. (2013) | Tecem considerações sobre as políticas de gestão de preservação e acesso ligadas à certificação, que devem ser apoiada por um conjunto de ferramentas metodológicas, incluindo descritivos, estudos de caso e modelos de custo para fornecer orientações sobre o desenvolvimento das melhores práticas em política de gestão e preservação de dados e infraestrutura para esses projetos. |
Abstract
Introduction - Regarding the concerns that prompted the emergence of digital curation, this study takes as an example the context of the production of large volumes of scientific information, which requires approaches that ensure its maintenance, reuse and valorization, considering its cost.
Objectives - It is intended to discuss the relevant issues regarding the costs of digital curation and to develop a framework model proposal for the analysis of costs in digital curation, including projects of a more practical nature. This means addressing the concept definition and the issue of costs, based on studies related to cost models.
Methodology - A literature review was carried out, contextualizing the issue of costs within digital curation, with data collected from Biblioteca do Conhecimento Online – B-On (Online Knowledge Library) and Repositórios Científicos de Acesso Aberto de Portugal – RCAAP (Scientific Open Access Repository of Portugal) as research literature sources. Then, a framework model scheme was developed based on the categories identified using the Constant Comparative Method, some related to the Open Archival Information System (OAIS) Reference Model and to the Digital Curation Centre (DCC) Life Cycle. This allowed the development of a content analysis of the perceptions collected from different authors, resulting in memos, of which this text is a summary.
Results / Conclusion - It is proposed a systematization of digital curation issues, which constitutes a framework model considered relevant for the analysis of costs in digital curation, including practical projects, which interconnects the DCC Life Cycle view of the digital object curation to the OAIS Reference Model approach, in a transversal logic seized by the cost models and plan/data management policies. It is concluded that a paradigm shift is occurring from a black-box perspective to another one that identifies costs and attempts to standardise predictive models for institutional use with the aim of promoting transparency, accountability, and capturing the interest of potential funding providers.
Note on Translation
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
