


Volume 10 Number 4
Information access in the art history domain: Evaluating a federated search engine for Rembrandt research
Abstract
The art history domain is an interesting case for search engines tailored to the digital humanities, because the domain involves different types of sources (primary and secondary; text and images). One example of an art history search engine is RemBench, which provides access to information in four different databases related to the life and works of Rembrandt van Rijn. In the current paper, RemBench serves as a case to (1) discover the requirements for a search engine that is geared towards the art history domain and (2) make recommendations for the design of user observation studies for evaluating the usability of a search engine in the art history domain, and in digital humanities at large.
A user observation study with nine participants confirms that the combination of different source types is crucial in the art history domain. With respect to the user interface, both free-text search and facet filtering are actively used by the observed participants but we observe strong individual preferences. Our key recommendation for specialized search engines is the use of faceted search (free text search combined with filtering) in combination with federated search (combining multiple resources behind one interface). In addition, the user study shows that the usability of domain-specific search engines can successfully be evaluated using a thinking-aloud protocol with a small number of participants.
1. Introduction
- Was Rembrandt’s “Reading Woman” in the Rijksmuseum painted on canvas or panel?
- Did Rembrandt paint dogs?
- How old was Titus when he died?
- Where is Rembrandt’s “Storm on the Sea of Galilee”?
- Find etchings after Rembrandt’s self portraits
2. Literature review
2.1. The information seeking behaviour of humanities scholars
“Recognize that humanities searches are often composed of several facet elements. Because the indexing for many databases is not optimally designed for queries of this sort, good online database searching in the humanities may actually be harder than for the sciences, even for the skilled online intermediary, and will almost certainly be difficult for the typical humanities end user.” [Bates 1996a, 9]
2.2. Usability testing and user interaction analysis for information seeking
- Query formulation and reformulation strategies in multi-query sessions are described by Lau and Horvitz [Lau and Horvitz 1999] and Rieh [Rieh 2006]. They distinguish query specification (making the query narrower by adding one or more terms), query generalization (making the query broader by removing one or more terms) and query reformulation (replacing one or more terms by other terms without making the query broader or narrower). The effect of query specification is generally a higher precision and lower recall of relevant results in the result set, while the effect of query generalization is the opposite. In the case of faceted search interfaces, query formulation does not only comprise the typing of textual queries, but also the selection of facet values. Kules et al. [Kules, Capra, Banta, and Sierra 2009] found in an eye-tracking study that users of a faceted search interface working on an exploratory search task spent about 50 seconds per task looking at the results, about 25 seconds looking at the facets, and only about 6 seconds looking at the query itself. These results suggest that facets are important for users with exploratory search tasks.
- For investigating how users process and evaluate the items returned in response to a query, important work has been done with eye-tracking experiments [Granka, Joachims, and Gay 2004]. One of the findings of this work is that users spend much more time looking at the results in the top five of the result list (especially the first and second result) than at the results in position six to ten. In the case of federated search, search results come from multiple information sources (so-called “verticals”) and are presented to the user in one result page. It is interesting to study how users interact with the combined result page [Ponnuswami, Pattabiraman, Wu, Gilad-Bachrach, and Kanungo 2011] and what the differences are in user behaviour for results from the different verticals [Spink and Jansen 2006]. Ponnuswami et al. [Ponnuswami, Pattabiraman, Wu, Gilad-Bachrach, and Kanungo 2011] address the challenge of “page composition”, where the goal is to create a combined result page with the most relevant information from the different verticals.
3. About RemBench
4. User study
4.1. Design, materials and procedure
- How satisfied are you with the answer found? (5-point rating scale)
- How satisfied are you with the use of RemBench for answering the question? (5-point rating scale)
- Please list the positive aspects of RemBench
- Please list the negative aspects of RemBench
4.2. Questions about Rembrandt
4.3. Annotation of the data
| Question | Facets used | Queries issued | Verticals used |
| How old was Titus when he died? | -titus | -Artists | |
| Which Works by Rembrandt and his students have been in the possession of Abraham Bredius? | -Person type -Content type |
-Abraham Bredius -Abraham Bredius possession -Bredius |
-Artists -Works of art |
| Was Rembrandt’s Reading Woman in the Rijksmuseum painted on canvas or panel? | -Content type -Location |
-Lezende vrouw | -Works of Art -RKD |
5. Results and analysis
- Question types: Which types of questions are asked by Rembrandt researchers? (Section 5.1);
- User-system interaction (Section 5.2):
- How many queries, facets and verticals do the users need to answer one question?
- How does the session length for RemBench compare to library search and general web search?
- What are the individual differences between users?
- How do users formulate and reformulate queries (query modification patterns)?
- User satisfaction (Section 5.3):
- How does usability satisfaction relate to answer satisfaction?
- How does user satisfaction differ between question types?
- What positive and negative comments did the users make?
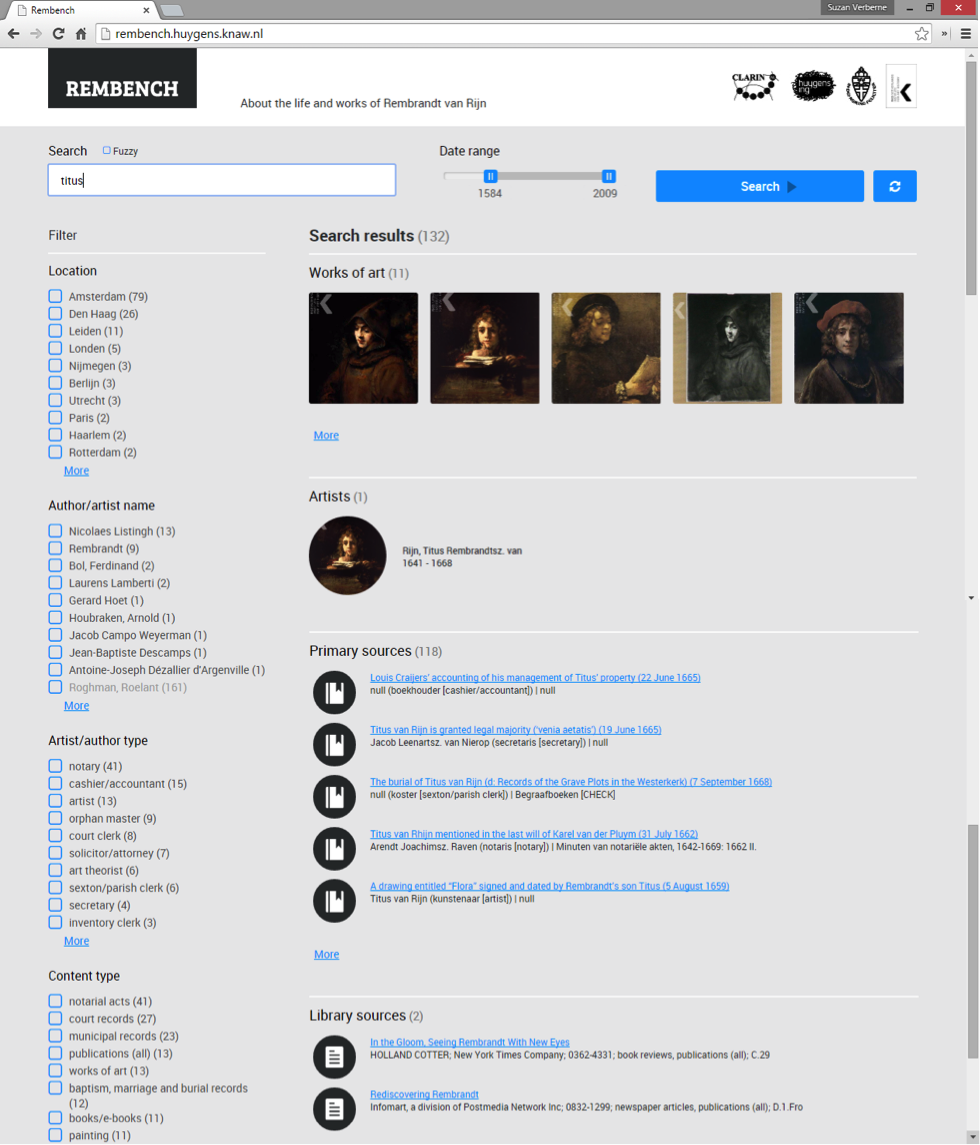
5.1. Which types of questions are asked by Rembrandt researchers?
| Type | Count | Examples (translated from Dutch) |
| Closed (yes/no; two options) | 17 | -Was Rembrandt’s Reading Woman in the
Rijksmuseum painted on canvas or panel? -Did Rembrandt know Jews? -Did Rembrandt paint dogs? |
| Factoid | 28 | -How old was Titus when he died? -How many works by Rembrandt are in private collections? -Where is Rembrandt’s Storm on the Sea of Galilee? |
| List | 16 | -Which paintings by Rembrandt have been in the collections of the
House of Orange-Nassau? -Which works by Rembrandt are in St. Petersburg? -Find etchings after Rembrandt’s self portraits |
5.2. User-system interaction
5.2.a. How many queries, facets, and verticals do the users need to answer one question?
| Mean (stdev) | Min-max | |
| Number of facets used | 0.86 (1.00) | 0-3 |
| Number of queries used | 2.11 (1.48) | 0-7 |
| Number of verticals used | 1.46 (1.03) | 0-5 |
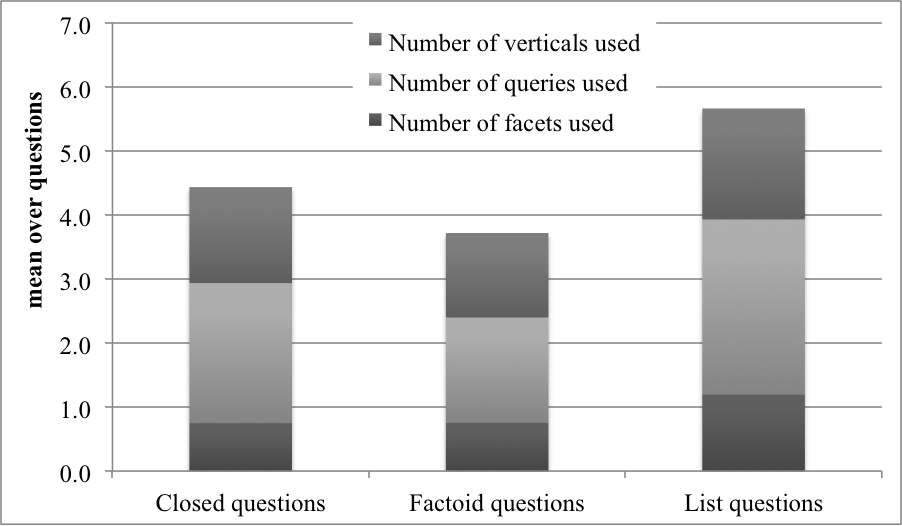
5.2.b. How does the session length for RemBench compare to library search and general web search?
- library search: data from The European Library (TEL) search logs, analysed by Verberne et al. 2010 [Verberne, Hinne, van der Heijden, Hoenkamp, Kraaij, van der Weide 2010][11]
- general web search in the early years of web search systems [Jansen, Spink, and Saracevic 2000]
- a more recent web search data set from 2006: the Microsoft Search (MSN) dataset that was distributed for the WSCD 2009 workshop,[12] earlier analysed by Hinne et al. 2011 [Hinne, van der Heijden, Verberne, and Kraaij 2011]
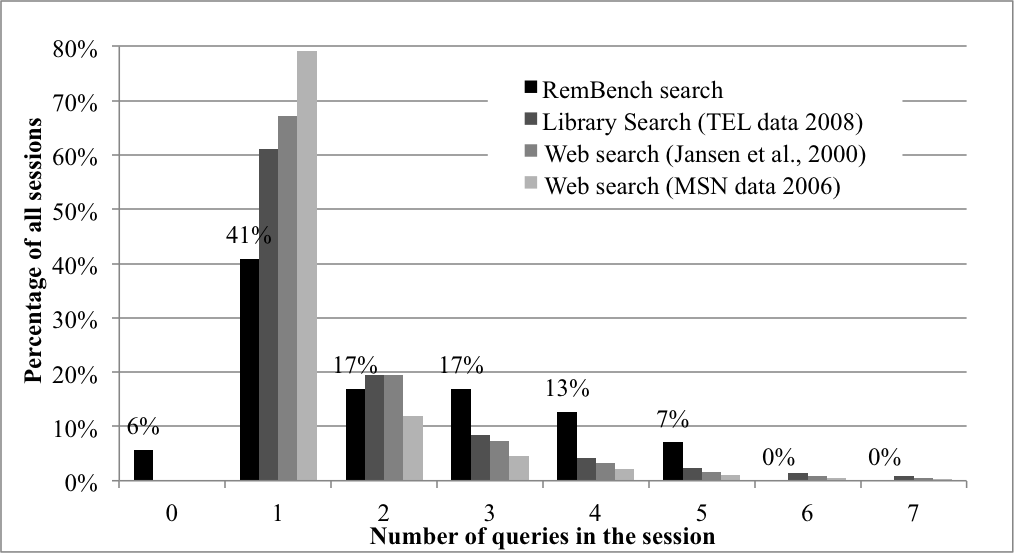
5.2.c. What are the individual differences between users?
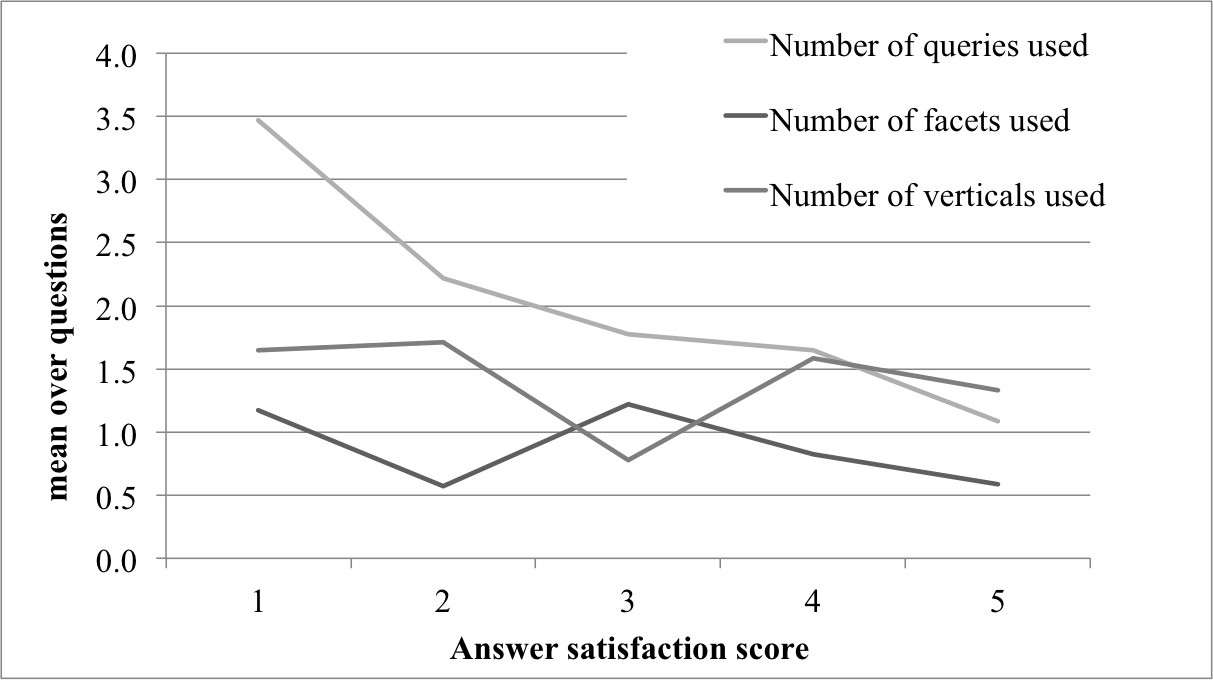
5.2.d. How do users formulate and reformulate queries (query modification patterns)?
- Request for additional results: the current query is the same as the previous one (same query is reissued, likely with different facet values);
- Generalization: the current query is a substring of the previous query. E.g. the query “students Rembrandt” followed by the query “students”;
- Specialization: the previous query is a substring of the current query. E.g. the query “winter” followed by the query “winter landscape”;
- Reformulation: the current query has at least one word in common with the previous query, but one is not a substring of the other. E.g. the query “Rembrandt England” followed by the query “Rembrandt travels”;
- New topic: the current query has no words in common with the previous query.[13] Note that the first query issued by a user by definition starts a new topic.
| In the RemBench data | In web search data | ||
| Number of queries | 150 | 2000000 | |
| New topic | 53 | 35.3% | 67.0% |
| Generalization | 26 | 17.3% | 2.2% |
| Reformulation | 25 | 16.7% | 12.4% |
| Specialization | 24 | 16.0% | 4.9% |
| New topic in same session | 16 | 10.7% | 16.6% |
| Request for additional results | 6 | 4.0% | 13.5% |
5.3. User satisfaction
5.3.a. How does usability satisfaction relate to answer satisfaction?
- The mean score that was obtained for answer satisfaction is 2.90, with a standard deviation of 1.46;
- The mean score that was obtained for usability satisfaction is 2.84, with a standard deviation of 1.27.
5.3.b. How does user satisfaction differ between question types?
| Difficult questions (Answer satisfaction score is 1) | Easy questions (Answer satisfaction score is 5) |
| What is the biggest (and smallest) painting by Rembrandt? | Was Rembrandt’s Reading Woman in the Rijksmuseum painted on canvas or panel? |
| How many brothers does Saskia have and when were they born? | How long has Willem Drost lived in Italy? |
| Are there any male portraits by Rembrandt known that are similar size to his Portrait of a young woman with a dog in Toledo? | Where were Rembrandt’s children baptized (in which church)? |
| Find mezzotints after Rembrandt’s works | When was Aert de Gelder born? |
| Where is Rembrandt’s Sacrifice of Isaac? | What is the provenance of the Night Watch?[15] |
| Did Rembrandt have grandchildren; if yes, where were they born? | Is Ferdinand Bol older or younger than Govert Flinck? |
| Find literature about Rembrandt by Haverkamp-Begemann. | |
| Find all works by Rembrandt with a sword on them | |
| Find still lifes by Rembrandt and literature about them |
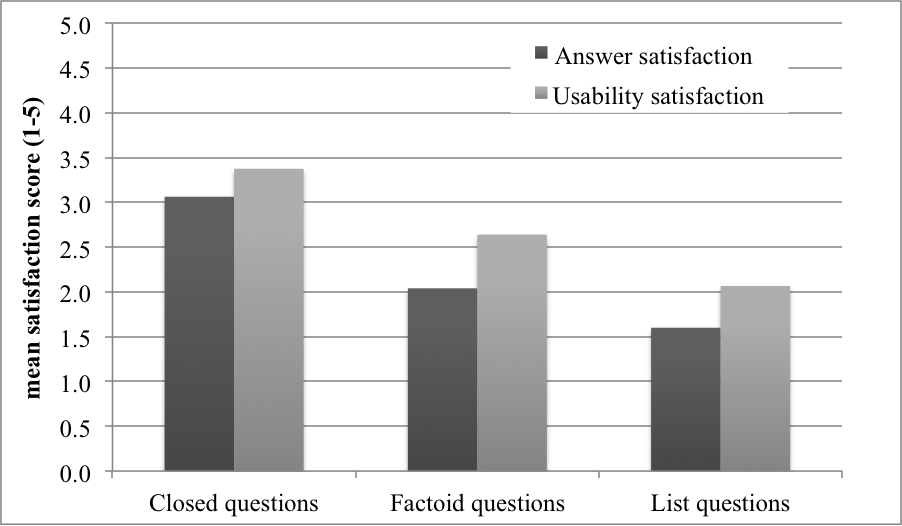
5.3.c. What positive and negative comments did the users make?
| Topic | Positive | Negative |
| Graphical user interface | -Clear colours, good font type, nice overview, good
layout |
- |
| Interaction design | -Easy to use -Search options are immediately clear -Results ordered by type |
-Sometimes difficult to choose between many search options
|
| Search functionality | -Searching possible in English and Dutch -Good filter options (especially date range and location) |
-It is not possible to search for works by one specific
artist -Differences in results between English and Dutch queries -It is difficult to find works of art with specific topics -It is sometimes difficult to find specific answers -It is difficult to get the intended number of results: either too many or too few -Searching sometimes takes a lot of time |
| Content | -Works of art, primary and secondary sources combined -Lots of information -Reliable sources in the search results -References to RKDexplore with even more information |
-Low quality of images |
6. Discussion
6.1. Requirements for a search engine in the art-history domain
- RemBench users enter more queries per session than web search users; the distribution of queries per session is more similar to sessions in digital library search. This reflects the informational nature of the questions in a specific topic domain, as opposed to the high proportion of navigational queries on the web. Still, the average number of queries needed per question is relatively low (2.0), which indicates that the RemBench search interface allows for efficient information seeking.
- The combination of different source types is highly important in the art history domain. Four databases were combined as four different verticals in the search interface. This was preferred by domain experts, and also highly valued by the participants of the user study. Especially the combination of works of art, primary and secondary sources was considered an important asset of RemBench.
- Both free-text search and facet filtering were actively used by the observed participants. There were individual differences in the frequency of use of queries and facets: Some users preferred free-text searching, while others had a preference for filtering facets. This finding confirms the value of faceted search interfaces for domain-specific information-seeking tasks.
- The users appreciated the presence of multi-lingual data (Dutch and English) in the connected databases. However, they were critical about the cross-lingual access to the data. In many cases, they had to try their queries in both English and Dutch in order to get the results that they wanted. This illustrates the challenge of managing databases with multilingual content and shows the importance of cross-lingual information access to multilingual data.
- A search environment for a highly specific domain (such as Rembrandt) requires domain-dependent treatment of the data and in some cases also of the queries. Domain-specificity requires pre-selection of relevant data from the connected databases (see Section 3). In addition, term discounting for the specific query term “Rembrandt” had to be implemented, because it was difficult for the participants to get the exact results they wanted for queries containing this high frequent term (see Section 5.3.c). More analysis in future work is required in order to answer the question that arises from the analysis: under what circumstances does a highly specific topic domain require domain-specific re-weighting of query terms, and when are the ordinary term weighting variables (term frequency, inverted document frequency) sufficient?
6.2. Recommendations for the design of a user observation study
7. Conclusion
Acknowledgements
Notes
Works Cited
Last updated:
Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations
Affiliated with: Literary and Linguistic Computing
Copyright 2005 -

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.