Classifying the Unclassified
Our first classification task was to train the classifier on the 54,289 articles
that were assigned categories of knowledge by the editors of the
Encyclopédie and to then apply this model to the 22,796
unclassified articles in an attempt to predict class membership for the articles
in question. Once classified, the twenty most frequent labels for the newly
classified articles were:
| Jurisprudence |
4276 |
| Art méchanique |
1260 |
| Géographie |
828 |
| Commerce |
802 |
| Anatomie |
643 |
| Marine |
557 |
| Histoire moderne |
475 |
| Architecture |
435 |
| Grammaire |
402 |
| Histoire naturelle. Ornithologie |
367 |
| Medecine |
363 |
| Géographie moderne |
347 |
| Art militaire |
311 |
| Histoire ecclésiastique |
308 |
| Géométrie |
306 |
| Géographie ancienne |
306 |
| Musique |
295 |
| Astronomie |
274 |
| Histoire naturelle. Botanique |
266 |
| Théologie |
215 |
Table 2.
Counts of top 20 most frequent classifications for previously
unclassified articles.
While this distribution of classes bears some resemblance to the overall
distribution cited above, we have no real way of verifying the accuracy of the
classifier given the unknown content/classes of the unclassified
articles.
[11] While it is entirely
plausible that 19% of the unclassified articles are concerned with Jurisprudence
in a general sense, it is also likely that Jurisprudence (which represents only 5%
of the classified articles) becomes of sort of “catch-all” category for the
classifier into which articles concerned with any specific aspect of law (i.e.
droit romain,
droit canonique,
droit
civil, etc.) are grouped.
The sample of results we examined reveal that the classifier performed reasonably
well. By this, we mean that some classifications seemed right on; some made a good
degree of sense, while others were perhaps a bit too general, failing to
accurately represent the specificity of the subject matter. Naturally, the more
than 22,000 newly generated classifications could not all be verified by hand, and
so we focused on major articles and a selection of smaller ones. We were
particularly encouraged by the assigned classifications for the 10 longest
unclassified articles. The
Discours Préliminaire,
d'Alembert's famous preface to the
Encyclopédie
detailing the intellectual underpinnings of the enterprise, comes back as
belonging to the class Philosophy.
[12] Going down the
list we see that the article “Anatomie” is assigned its
own classification in Anatomy and “Chimie” is rightly
placed into Chemistry, results we had originally hoped were easy enough for the
algorithm to attain. Most of the classifications, however, don't fall into such
clear categories. For example, “Venerie” — the art of
hunting — was assigned to Natural History; the philosophical article “Eclectisme” to the History of Philosophy, etc. Indeed,
while these and the better part of the predicted classifications can be justified
on a general level, we had to concede that the overall utility of this task was
somewhat questionable. Quite simply, as we mention above, there was just too much
data to sort through. The new labels were often interesting, but we were not able
to study them easily or thoroughly enough to come to any deeper understanding
about how the
philosophes structured knowledge or
indeed how the
Encyclopédie itself fits together.
Thus, trying to develop an experiment that could generate more legible results, we
decided instead to leverage the information given us by the editors in exploring
the known classifications and their relationship to each other and then later, to
consider the classification scheme as a whole by examining the general
distribution of classes over the entire work as opposed to individual
instances.
Classified vs. Classified — Feature set evaluation
Having run a set of predictive classification experiments on the unclassified
articles, our next task was an attempt at what we have named "comparative"
classification, wherein we train the classifier on two particular classes, and
then reclassify them in an effort to determine how separable they are and to
ascertain which features best distinguish articles from the two sets. The goal
here has less to do with the accuracy of the classifications than with the feature
sets that are generated during the classification task. Any two classes can be
compared. Feature weights are generated using the Naive Bayes Perl module written
by Ken Williams. These weights represent the conditional probability of a feature
f given a class c and are generated based on their frequency in the known
articles.
[13]
To give an example of this sort of comparative classification, 889 articles
classified as “Histoire ancienne” were compared with 1194 articles in the
“Histoire moderne” class and the following features and their weights were
extracted as the most relevant in determining class membership:
| étoient |
0.04356 |
| avoit |
0.03705 |
| romains |
0.02472 |
| avoyer |
0.02455 |
| an |
0.02341 |
| peuple |
0.02271 |
| chez |
0.02188 |
| sous |
0.02182 |
| tems |
0.02170 |
| mot |
0.02146 |
| empereur |
0.02146 |
| g |
0.02122 |
| appelloit |
0.01880 |
| premier |
0.01847 |
| nous |
0.01802 |
| encore |
0.01783 |
| après |
0.01763 |
| homme |
0.01756 |
| dieu |
0.01683 |
| rome |
0.01683 |
Table 3.
Conditional probabilities of top 20 most common words in articles from
Histoire ancienne
| roi |
0.03744 |
| ordre |
0.02870 |
| prince |
0.02390 |
| sous |
0.02314 |
| nommer |
0.02180 |
| titre |
0.02165 |
| empire |
0.02065 |
| chevalier |
0.02046 |
| officier |
0.02039 |
| tems |
0.02030 |
| étoient |
0.02003 |
| premier |
0.01959 |
| empereur |
0.01903 |
| porter |
0.01891 |
| état |
0.01871 |
| mot |
0.01851 |
| avoit |
0.01823 |
| prendre |
0.01814 |
| maître |
0.01814 |
| sans |
0.01780 |
Table 4.
Conditional probabilities of top 20 most common words in articles from
Histoire moderne
The overall performance of the classifier came in at 95.63%, which tells
us that while both belong to the same “branch” of science, namely History,
the ancient and the modern are nonetheless significantly distinguishable from one
another. When considering the two lists of features, one immediately notices that
the results make good sense, i.e., we find more verbs in the past tense (
avoient ,
étoient,
etc.) in the Ancient History articles as well as references to antiquity (
romains ,
empereur,
rome, etc.). The
single-letter feature “g” is the signature of the Abbé Mallet who was the
author of a significant portion of the articles on Ancient History. Interestingly,
some of the features occur in both lists, which is more than likely a result of
the close relationship and dialogue between the two classes. In the feature set
for Modern History, we find references to forms of government that quite rightly
belong to the modern period (
état,
prince,
roi,
chevalier, etc.) and the notable absence of the word “
dieu
” (“god”).
We can also run comparative classification tasks on seemingly dissimilar classes
of knowledge such as the 682 Literature articles and the 200 articles dealing with
Physics. Not surprisingly, we obtain a very high rate of success for this sort of
classification, in this case, 99.29%:
| nous |
0.03330 |
| mot |
0.02902 |
| avoit |
0.02607 |
| étoient |
0.02294 |
| livre |
0.02283 |
| ancien |
0.02149 |
| je |
0.02117 |
| tems |
0.02030 |
| bien |
0.01997 |
| encore |
0.01963 |
| sans |
0.01956 |
| vers |
0.01907 |
| dieu |
0.01835 |
| auteur |
0.01820 |
| latin |
0.01785 |
| usage |
0.01742 |
| devoir |
0.01738 |
| notre |
0.01695 |
| homme |
0.01691 |
| chose |
0.01671 |
Table 5.
Conditional probabilities of top 20 most common words in articles from
Littérature.
| corps |
0.05394 |
| air |
0.04216 |
| eau |
0.04185 |
| nous |
0.03507 |
| froid |
0.02597 |
| chaleur |
0.02584 |
| monsieur |
0.02580 |
| degré |
0.02296 |
| moins |
0.02251 |
| fort |
0.02242 |
| glace |
0.02196 |
| couleur |
0.02169 |
| feu |
0.02160 |
| lorsque |
0.02109 |
| effet |
0.02048 |
| peu |
0.01991 |
| rayon |
0.01986 |
| fluide |
0.01962 |
| mouvement |
0.01952 |
| trouver |
0.01948 |
Table 6.
Conditional probabilities of top 20 most common words in articles from
Physique
The feature scores from this model are what we would expect. The Literature class'
most significant features are those words pertaining to language and grammar (
mot, livre,
vers, auteur,
latin, usage,
etc.) whereas the Physics class is dominated by materialistic terminology (
corps, air,
eau, degré,
fluide, mouvement, etc.) consistent with the scientific writings of the
period.
Evaluation of these feature sets can be invaluable when testing certain
hypotheses, such as word usage differences across similar disciplines or between
authors. In this particular case, the features provide an intuitive illustration
of the differences between these two distinct classes of knowledge. While features
are simply terms that the algorithm finds statistically representative of a
particular class, the feature sets as a whole can also give a snapshot of the
make-up of the individual classes or indeed of larger concepts more generally.
From the list for literature, for example, we get a sense of the importance that
classical Roman authors still had for the
philosophes with the terms
“ancien” (“ancient”) and
latin.
“Vers” (“verse”) perhaps reflects the fact that versification was a
predominant aspect of literary style, whether in poetic, dramatic, and other
writing at that time. Terms such as “mot” (“word”) and “usage”
(“use”) might point to the 18th century's expansive, belle-lettristic
sense of literature that we discuss below. In a more general manner, feature sets
provide us with an expanded thesaurus for any given classification task -- leads
for further investigation and study -- that can then be exploited by a more
traditional full text analysis system.
[14]
Reclassifying the Classified — the Ontology of the Encyclopédie
Finally, we applied the model assembled for our first experiment — trained on all
of the known classifications — onto all of the already classified articles. By
this, we mean that we effectively ignored any given classes of knowledge, treating
each article as if it were unclassified, and then assigned class membership using
the algorithm described above. Here our goal in the results analysis was twofold:
first, we were curious as to the overall performance of our classification
algorithm, i.e., how well it correctly labeled the known articles; and secondly,
we wanted to use these new classifications to examine the outliers or
misclassified articles in an attempt to understand better the presumed coherency
and consistency of the editors' original classification scheme.
We achieved a 71.4% success rate in the re-categorization of the 54,289 classified
articles, a performance that could perhaps be improved with a more accurate
morphological stemmer and the inclusion of n-grams as features, fucnctions we
intend to implement in the future. Nonetheless, developing a model to reliably
guess an article's given class of knowledge is ultimately not our primary concern
as even a perfect model, while impressive in terms of performance, could only
yield that which we already know, namely the assigned classes of knowledge. The
sheer size and complexity of the Encyclopédie,
drawing its contents from hundreds of distinct writers, all but guarantees a lower
rate of performance for any classification algorithm. This fact need not be
discouraging however, as we are more interested in exploring the use of these text
mining techniques as knowledge discovery tools, uncovering previously unnoticed
connections and classifications, such as the particular use of the class
“Literature” outlined below, rather than simply using these approaches as
a statistical platform for hypothesis testing.
The twenty most frequent classes after re-classification:
| Géographie |
3926 |
| Géographie ancienne |
3492 |
| Géographie moderne |
3273 |
| Jurisprudence |
2552 |
| Commerce |
2104 |
| Art méchanique |
1662 |
| Histoire naturelle. Botanique |
1615 |
| Marine |
1575 |
| Histoire moderne |
1514 |
| Mythologie |
1334 |
| Architecture |
1213 |
| Grammaire |
1111 |
| Histoire ancienne |
1061 |
| Histoire ecclésiastique |
781 |
| Medecine |
746 |
| Histoire naturelle |
727 |
| Littérature |
646 |
| Maréchallerie |
592 |
| Morale |
573 |
| Jardinage |
566 |
Table 7.
The 20 most frequent classes of knowledge by number of articles after
re-classification.
When comparing the results to the original classifications we note that the class
“Grammar” falls out of the top ten while “Art méchanique,” which is
not included in the original top twenty, ranks as the sixth most frequent class.
The Grammar class is known to be problematic as Diderot frequently used this
seemingly innocuous label to hide more polemical entries.
[15] As for the “Art méchanique”
category, we suspect that many of the overly specific classes dealing with the
mechanical arts were subsumed into this larger, more inclusive set. By and large
the rest of the classes are consistent with the overall distribution in the
Encyclopédie although the rankings differ slightly.
The most interesting results here come from the examination of misclassified
articles, which belie vocabularies that do not belong probabilistically to their
assigned categories. Upon analyzing a random subset of the misclassified articles,
we identified three distinct types of misclassifications. First, there are
articles whose original classification was too infrequent; for example, the
article “Accrues” (metal rings used to knit together
fishing net) is the sole member of the class “Marchands de Filets” (net
merchants) and was placed into the more general class of “Pêche” (fishing).
There are also articles whose vocabularies mislead the classifier. One such case
is the article “Achées” (a type of worm used in
bait-fishing), originally classified as “Pêche,” it was later assigned to the
class “Jardinage” (gardening). The article is in fact less a description of
anything to do with fishing, but rather contains instructions on how to find and
cultivate bait worms in a garden. Finally, there are entries whose predicted
class, while incorrect, seems more logical than the original. The article “Tepidarium,” which describes an ancient Roman bathhouse,
would appear to have more in common with its predicted class, Architecture, than
the one assigned by the editors, namely Literature. Certainly our judgment that
the predicted class is more appropriate than the original class of knowledge is
biased by our modern epistemological paradigm, but this does not necessarily mean
that the original system of classification was entirely consistent and coherent.
Naturally then, applying our model onto other 18th century French texts should
provide further insight into the power of the classifier and more importantly,
into the ontology originally laid out by the philosophes.
Classification outside of the Encyclopédie
The
Journal de Trévoux, or
Mémoires pour l'Histoire des Sciences & des Beaux-Arts, was one of
the most influential 18th century French periodicals. A sort of literary/scholarly
journal reviewing and commenting on a wide variety of contemporary publications,
the
Journal de Trévoux dealt with almost every
discipline of knowledge. Given the great variety of subject matter contained in
this collection we felt it would be a natural choice for us to begin studying the
relationship of the Encyclopédie ontology to other 18th century texts. Of course,
the 18th century in France was a time of intellectual ferment and, as in most
historical moments, there existed more than one approach to the classification of
the known world. And, indeed, the
philosophes' intellectual and
political bent made their way of organizing ideas different from that of other
thinkers, particularly the Jesuits who were behind the
Journal de Trévoux. Knowing this, we wanted to test the degree of
overlap between the structure of knowledge in the
Encyclopédie and the
Journal de Trévoux,
discovering in the process the commonalities, differences, and unique aspects of
each. We hoped this experiment would give us a "slice of life" look at the
intellectual milieu of the day, or at least provide an insight into the presumed
differences in discourse between the two camps. To this end, we processed the
ARTFL Project's 109 volumes of the
Journal de
Trévoux, splitting them into 1,027 separate articles. Extending from 1751
to 1757, this collection covers the years during which the editors of the
Journal engaged in a fierce polemic with the
encyclopédistes concerning the publication of the
Encyclopédie.
[16] Our
previous model, trained on all of the classified
Encyclopédie articles, was thus applied to the Trévoux articles,
assigning each with a predicted class of knowledge. The twenty most frequent
assigned classes are listed below:
| Littérature |
317 |
| Morale |
86 |
| Géographie moderne |
61 |
| Théologie |
54 |
| Philosophie |
50 |
| Histoire moderne |
46 |
| Belles lettres |
45 |
| Astronomie |
35 |
| Métaphysique |
30 |
| Histoire ecclésiastique |
26 |
| Physique |
22 |
| Art militaire |
18 |
| Economie politique |
18 |
| Géographie |
16 |
| Medecine |
16 |
| Histoire romaine |
14 |
| Peinture |
14 |
| Histoire |
14 |
| Histoire naturelle |
13 |
| Chimie |
12 |
Table 8.
The 20 most frequent classes of knowledge assigned to the Trévoux
articles using the Encyclopédie model.
A cursory glance at these results gives us a general idea about the most
significant themes found in the Journal de Trévoux;
themes that correspond nicely to our preconceived notions concerning the Journal, its writers and subject matter. Along these
lines, it is not surprising to find in a Jesuit publication such as this a greater
emphasis on articles about Literature, Morality, Theology, and Philosophy.
However, the surprising fact that more than 1/3 of the 1000 articles were assigned
the label of Littérature caused us to question
somewhat the performance of the classifier and ultimately, to reconsider our
modern notion of Literature when applied to the specific instances of this
classification.
In the first edition (1694) of the Dictionnaire de l'Académie
française the entry for “Littérature” reads
thus: “
Litterature. s. f. Erudition, doctrine. Grande litterature. profonde litterature. il est homme de
grande litterature. il n'a point de litterature. il a beaucoup de
litterature.
” and indeed the definition changes little by the fourth edition of 1762:
“
LITTÉRATURE. s.f. Érudition, doctrine. Grande littérature. Profonde littérature. Il est homme de grande
littérature. N'avoir point de littérature. Avoir beaucoup de littérature.
Un ouvrage plein de littérature. Ce mot regarde proprement les
Belles-Lettres.
” The addition of the last sentence, “This
word is properly used in regard to Belles Lettres,” in the 1762 edition
seemingly restricts this particular form of erudition to the more traditionally
literary realm of the “Belles-Lettres,” or Poetry and Rhetoric. The
definition offered by the Jesuit editors of the Dictionnaire
de Trévoux (1742) differs only slightly from that of the Academy:
“LITTÉRATURE, s. f. Doctrine, connoissance
profonde des Lettres. Doctrina, litteratura,
eruditio.” While these definitions shed little light as to why the
Encyclopédie literature class should be so
prevalent in the classification of such a diverse collection of articles, many of
which deal with the Sciences and Natural History, the ambiguity of this erudite
possession of “
littérature
” and “
lettres
” should nonetheless cause us to broaden our understanding of these terms as
they were used in the mid-18th century.
We thus began a more thorough investigation of the Literature category by
examining five randomly selected articles belonging to the assigned class
“Littérature” in the
Journal de Trévoux.
While some categorizations make sense as literature — e.g., the article “Nouvelles Litteraires,” a sort of literary “news of the
day”; and, less convincingly, a commentary on Rousseau's first discourse —
others have ostensibly nothing to do with our modern idea of Literature — e.g.,
articles commenting on a history of jurisprudence, a treatise on diseases, and a
compilation of treatises on Physics and Natural History
[17]. This apparent anomaly necessarily leads us back to the
Encyclopédie and the articles belonging to the class of
knowledge Literature, which serve as the basis for these class assignments.
As we mentioned above concerning the reclassification of the article “Tepidarium,” there are a great many articles whose
original classifications seem inappropriate. This phenomenon is all the more
evident when examining the reclassification of the Literature articles, the
majority of which deal more with Ancient History, Mythology, and Architecture than
with accepted literary issues. Of the 682 Literature articles, 460 were written by
the Chevalier de Jaucourt, author of more than 17,000
Encyclopédie entries. Jaucourt is known to have borrowed extensively
from other sources and thus, we attributed these inconsistencies to intellectual
laziness, given the enormous number of articles for which he was
responsible.
[18] Upon closer examination of the Literature class of knowledge
however, this characterization proves unjust.
Indeed, the article titled “Littérature” belongs not to
its own class of knowledge, but rather to three seemingly unrelated and disparate
classes: Sciences,
Belles-Lettres, and Antiquity. The text of the
article, written by Jaucourt, is in fact a polemic advocating a universal
erudition and an expanded definition of what it means to possess a great
literature — in a word to be literate. Jaucourt includes a
renvoi to
the article “Lettres” in an effort to define better this notion of
Literature. Following the cross-reference we find that the article in question,
“Lettres,” an article that normally falls innocuously amongst numerous
similarly titled entries, is the sole member of the class “Encyclopédie,”
suggesting that the idea of literacy is essential to the entire encyclopedic
enterprise. Here, Jaucourt's understanding of “Lettres” as a much larger
category of knowledge than “belles-lettres” or even the Humanities as a whole
(
les lettres humaines), harkens back to the Classical acceptation
of the term which encompassed all areas of human understanding from Epic Poetry to
Physics. The inter-connectedness of knowledge, both literary and scientific, is
thus the essence of Jaucourt's idea of encyclopedic literacy, wherein “
il en résulte que les lettres & les
sciences proprement dites, ont entr'elles l'enchaînement, les liaisons,
& les rapports les plus étroits; c'est dans l'Encyclopédie qu'il importe de le démontrer
” (“the result is that Letters and
Sciences, properly speaking, have between each other a strong and direct
network of links and relationships; it is in the Encyclopaedia that the
demonstration of this network becomes important”).
[19]



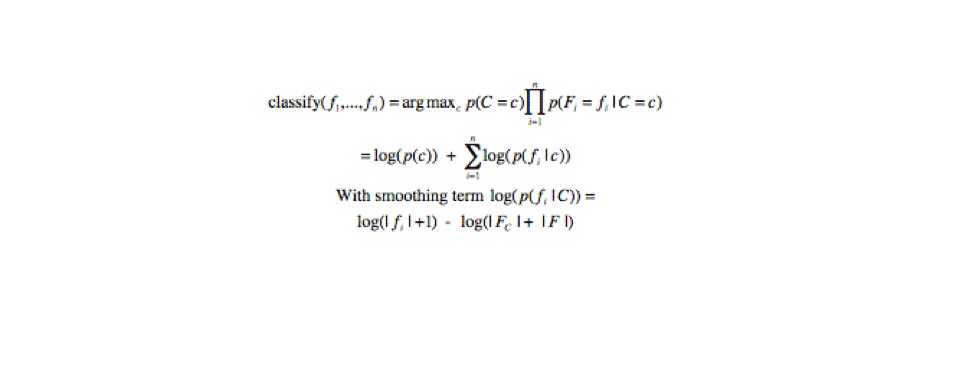 Williams' Perl module can be
downloaded at http://search.cpan.org/~kwilliams/Algorithm-NaiveBayes-0.04/lib/Algorithm/NaiveBayes.pm.
Williams' Perl module can be
downloaded at http://search.cpan.org/~kwilliams/Algorithm-NaiveBayes-0.04/lib/Algorithm/NaiveBayes.pm.