


Volume 6 Number 2
The Design of an International Social Media Event: A Day in the Life of the Digital Humanities
Abstract
A Day in the Life of the Digital Humanities (Day of DH) is a community documentation project that brings together digital humanists from around the world to document what they do on one day, typically March 18. The goal of the project, which has been run three times since 2009, is to bring together participants to reflect on the question, “Just what do computing humanists really do?” To do this, participants document their day through photographs and commentary using one of the Day of DH blogs set up for them. The collection of these journals (with links, tags, and comments) is, after editing, made available online. This paper discusses the design of this social project, from the ethical issues raised to the final web of journals and shares some of the lessons we have learned. One of the major challenges of social media is getting participation. We made participating easy by personally inviting a seed group, choosing an accessible technology, maintaining a light but constant level of communication prior to the event, and asking only for a single day of commitment. In addition, we tried to make participation at least rewarding in formal academic terms by structuring the Day of DH as a collaborative publication. In terms of improvements, we have over the iterations changed the handling ethics clearances for images and connected to other social media like Twitter.
1. Introduction
2. About the Project
2.1 Conception
The situation is even worse in the digital humanities where people not only do not know what we do as academics, but also seldom know what “humanities computing” or the “digital humanities” are. Contributing to this problem is the usual divergence of views within the field as to how to define it and how to name it. A Day in the Life of Digital Humanities addresses the question of definition by posing the question “what do we do” much as Ayers did. Rather than summarizing what he does, Ayers broke down and shared each step of his own work week. The Day of DH 2009 follows his example and expands upon it, organizing a participatory community to reflect as a community.In the eyes of most folks, a professor either portentously and pompously lectures people from his narrow shaft of specialized knowledge, or is a bookworm – nose stuck in a dusty volume, oblivious to the world [Ayers 1993].
2.2 Execution of the Project
- Develop project plan
- Research ethics proposal
- Invite selected participants personally
- Develop wiki with documentation
- Issue public invitation
- Set up blogging technology and test
- Communicate with participants leading up to the Day
- Communicate with participants after the Day
- Check of photo permissions
- Proof entries and tag
- Delete empty blogs
- Prepare tagged (TEI) dataset
- Prepare for sharing
- Review iteration and start planning for next year
2.3 Technical Design, Export, and Transformation
3. Preliminary Analysis
3.1 Answering the Question
3.2 Participation
| Country | Number of Participants |
| Canada | 30 |
| United States | 23 |
| Great Britain | 13 |
| Ireland | 5 |
| Germany | 4 |
| Slovenia | 1 |
| Australia | 3 |
| Luxembourg | 1 |
| Italy | 1 |
| Sweden | 1 |
| Poland | 1 |
| Switzerland | 1 |
| Netherlands | 1 |
| Total | 85 |
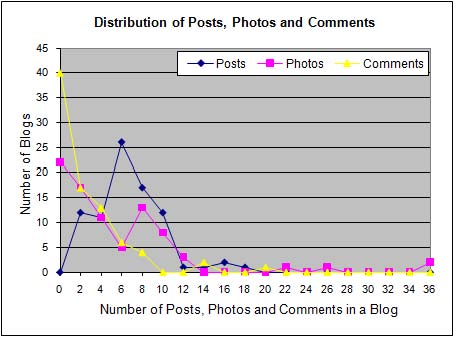
3.3 The Tagging
3.4 Analyzing the Tagged Dataset

| digital | 402 |
| day | 398 |
| work | 362 |
| I'm | 228 |
| humanities | 256 |
| time | 253 |
| project | 243 |
| students | 189 |
| research | 177 |
| today | 165 |
| working | 154 |
| meeting | 128 |
| class | 121 |
| people | 119 |
| DH | 116 |
| home | 101 |
| good | 98 |
| text | 97 |
| data | 96 |
| DDH-EarlyMorning | 6 tags |
| DDH-Morning | 189 tags |
| DDH-Afternoon | 167 tags |
| DDH-Evening | 62 tags |
| DDH-Night | 38 tags |
| DDH-AllDay | 11 tags |
| DDH-Home | 112 tags |
| DDH-Office | 98 tags |
| DDH-Outside | 25 tags |
| DDH-Class | 22 tags |
| DDH-CoffeeHouse | 19 tags |
| DDH-Lab | 18 tags |
| DDH-ProjectWork | 209 tags |
| DDH-AdminService | 84 tags |
| DDH-Email | 81 tags |
| DDH-Meeting | 91 tags |
| DDH-Conference | 32 tags |
| DDH-Class | 22 tags |
| DDH-Lab | 18 tags |
| DDH-Reflecting | 113 tags |
| DDH-Teaching | 100 tags |
| DDH-Research | 84 tags |
| DDH-Reading | 65 tags |
| DDH-Programming | 55 tags |
| DDH-Writing | 54 tags |
| DDH-Blogging | 31 tags |
| DDH-DataCollection | 19 tags |
| DDH-Learning | 16 tags |
| DDH-Editing | 15 tags |
| DDH-Gaming | 5 tags |
4. What Worked and What Didn't Work
4.1 What worked
4.2 What Didn't Work
5. Theorizing the Project
5.1 Reflection in the Digital Humanities?
Appendix: A Day in the Life of the Digital Humanities: About the Collective Dataset
Introduction
- The individual participants wrote their entries in a WordPress MU blog set up for the project.
- We allowed the participants time, after the day, to update and edit their entries.
- In some cases we removed the empty blogs of potential participants who were not able to blog their day.
- We exported the blogs from WordPress in the XML format that they provide. WordPress unfortunately escapes the content of the entries as CDATA marked entries as the tagging within tends to vary depending on the user. Below is an example from the original export of Geoffrey Rockwell’s blog. Note how WordPress adds its own tags that with square brackets, [ and ] for the caption of the image:
<post timestamp="March 18th, 2009 at 9:18 am MDT"> <title>Email and News</title> <tags>DDH Morning,DDH-AboutDDH,DDH-AdminService,DDH-Blogging,DDH-Email,DDH-Home</tags> <categories>Various</categories> <![CDATA[ Needless to say I woke up over an over lat night worrying about the Day of DH project. I don't know how many times I started my first post in twilight dreams. Anyway, I don't have a meeting until 10:00am so I'm starting the day in my corner by the window checking e-mail and doing various online tasks from my to do list like posting a news item on the <a href="http://portal.tapor.ca">TAPoR portal</a> and blogging the project on <a href="http://www.philosophi.ca/theoreti/?p=2415">theoreti.ca</a> (my usual blog). There seems to be something circular about blogging about blogging. Perhaps I should go twitter too. [caption id="attachment_30" align="aligncenter" width="300" caption="Laptop and Books"]<img class="size-medium wp-image-30" src="http://ra.tapor.ualberta.ca/~dayofdh/GeoffreyRockwell/files/2009/03/img_2579-300x225.jpg" alt="Laptop and Books" width="300" height="225" />[/caption] A quick glance at e-mail shows that nothing blew up with our blog system and the discussion is friendly. It will take me an hour to get through all the e-mail and little tasks. Why has e-mail become such a chore? ]]> </post> - We used XSLT and scripts to clean up the XML, to unescape the content, and to try to standardize the tagging of the content as much as possible. We tried to make the XML well-formed and able to display in a browser as the author saw it.
- We tagged all the entries with our own “DDH-" prefixed categories. Examples include:
The list of possible tags is as follows:<category domain="tag" nicename="ddh-communication">DDH-Communication</category> <category domain="tag" nicename="ddh-conference">DDH-Conference</category> <category domain="tag" nicename="ddh-morning">DDH-Morning</category> <category domain="tag" nicename="ddh-projectwork">DDH-ProjectWork</category>DDH-Communication, DDH-Email, DDH-DataCollection, DDH-Editing, DDH-Writing, DDH-Reading, DDH-Blogging, DDH-Reflecting, DDH-Programming, DDH-Visualization DDH-AdminService, DDH-Travel, DDH-Meeting, DDH-ProjectWork, DDH-Teaching, DDH-Learning, DDH-Research, DDH-Conference DDH-Office, DDH-Home, DDH-Outside, DDH-Class, DDH-Lab, DDH-CoffeeHouse DDH-EarlyMorn, DDH-Morning, DDH-Afternoon, DDH-Evening, DDH-Night, DDH-AllDay DDH-Other, DDH-AboutDDH, DDH-Biography
- We lightly edited the content for obvious typos and redundant tags. We did this partly to make sure that we had read all the entries. We were also checking for spam comments (which did creep in and which were deleted) and inappropriate content.
- In collaboration with the Kompetenzzentrum für elektronische Erschließungs- und Publikationsverfahren in den Geisteswissenschaften, University of Trier, Germany, the data was then transformed into a TEI “A day in the life of the Digital Humanities” customization.
Structure of blog entries
<item>
<title>The title the author gave the item.</title>
<dc:creator>The author’s name collapsed into one word
like “GeoffreyRockwell”</dc:creator>
<wp:post_date>2009-03-18 16:08:40</wp:post_date>
<wp:post_date_gmt>2009-03-18 22:08:40</wp:post_date_gmt>
<description/>
<edited>Initials of the person who did the editing
and a short description of what they did.</edited>
<tags>
<category domain="tag" nicename="add-new-tag">Add new tag</category>
More tags
</tags>
<content:encoded>The content of the entry in some mix of HTML.</content:encoded>
<comments>
<wp:comment>
<wp:comment_id>2</wp:comment_id>
<wp:comment_author>The author of the comment.</wp:comment_author>
<wp:comment_author_url/>
<wp:comment_date>2009-03-18 17:05:01</wp:comment_date>
<wp:comment_date_gmt>2009-03-18 23:05:01</wp:comment_date_gmt>
<wp:comment_content>The text of the comment.</wp:comment_content>
<wp:comment_type/>
<wp:comment_parent>0</wp:comment_parent>
<wp:comment_user_id>0</wp:comment_user_id>
</wp:comment>
More comments
</comments>
</item>
TEI Customisation
Day of Digital Humanities Corpus Skeleton
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/css" href="stage2-xml-style.css"?>
<teiCorpus xmlns:tei="http://www.tei-c.org/ns/1.0"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:wfw="http://wellformedweb.org/CommentAPI/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:wp="http://wordpress.org/export/1.0/"
xmlns:excerpt="http://wordpress.org/export/1.0/excerpt/">
<teiHeader type="corpus">
<!-- Corpus header here-->
</teiHeader>
<TEI xml:id="DDHblogd1e4">
<teiHeader type="text">
<!--Text header here-->
</teiHeader>
<text type="channel">
<front>
<!--front matter here-->
</front>
<body>
<!--one or more item elements (i.e. blog entries) here-->
</body>
</text>
</TEI>
<!--...-->
</teiCorpus>
Download
- This “About the Dataset“ explanation of the Dataset in PDF.
- The XML Dataset as a single XML file.
- A directory with all the images linked to from the entries.
- Associated documentation of the encoding.
Participants
- William Allen - Arkansas State University
- Rafael Alvarado - Dickinson College
- Jon Bath - University of Saskatoon
- Craig Bellamy - King's College London
- Brett Bobley - National Endowment for the Humanities
- Matthew Bouchard - University of Alberta
- John Bradley - King's College London
- Susan Brown - University of Guelph
- Kai-Christian Bruhn (link to user page) - University of Applied Sciences Mainz
- Lou Burnard - Oxford University Computing Services
- MatthewCarlos (link to user page) - Europäische Universität für Interdisziplinäre Studien
- Amanda Cash - College of Lake County
- James Chartrand - McMaster University
- Frédéric Clavert - Centre Virtuel de la Connaissance sur l'Europe (Luxembourg)
- Richard Cunningham - Acadia University
- Shawn Day - Digital Humanities Observatory
- Teresa Dobson - University of British Columbia
- Alastair Dunning - Joint Information Systems Committee (JISC), UK
- Michael Eberle-Sinatra - Université de Montréal
- Kathryn Eccles - Oxford Internet Institute, University of Oxford
- Maureen Engel - University of Alberta
- Domenico Fiormonte - Roma Tre
- Julia Flanders - Brown University
- Amanda French - New York University
- Alan Galey - University of Toronto
- Alejandro Giacometti - University of Alberta
- Joseph Gilbert - University of Virginia
- Matthew K. Gold - New York City College of Technology, CUNY
- Sean Gouglas - University of Alberta
- Katherine D. Harris - San Jose State University
- Steven Hayes - Sydney University
- Susan Hesemeier - University of Toronto
- Miran Hladnik - University of Ljubljana
- Martin Holmes - University of Victoria
- Kevin Kee - Brock University
- Viola Lasmana - San Francisco State University
- K Faith Lawrence - Digital Humanities Observatory
- Cara Leitch - University of Victoria
- Andrew Mactavish - McMaster University
- Ingrid Mason - University of Sydney
- Willard McCarty - King's College London
- Rudy McDaniel - University of Central Florida
- Chris Meister - Universität Hamburg
- Megan Meredith-Lobay - University of Alberta
- Federico Meschini - De Montfort University
- Aimee Morrison - University of Waterloo
- Kay Muhr - Queen's University Belfast
- Martin Müller - University of Alberta
- Elaine Murphy - Trinity College Dublin
- John Newman - University of Alberta
- Ashton Nichols - Dickinson College
- Bethany Nowviskie - University of Virginia
- Julianne Nyhan - Universität Trier
- Daniel O'Donnell - University of Lethbridge
- Marcel O'Gorman - University of Alberta
- Piotr Organisciak - University of Alberta
- Roger Osborne - University of Queensland
- Trevor Owens - Center for History and New Media
- Dot Porter - Digital Humanities Observatory
- Merrilee Proffitt - OCLC Research
- Stephen Ramsay - University of Nebraska-Lincoln
- Kamal Ranaweera - University of Alberta
- Torsten Reimer - King's College London
- Geoffrey Rockwell -University of Alberta
- Stan Ruecker - University of Alberta
- Jan Rybicki - Uniwersytet Pedagogiczny
- Patrick Sahle - University of Cologne
- Susan Schreibman - Digital Humanities Observatory, Dublin
- Alexandre Sevigny - McMaster University
- Stéfan Sinclair - McMaster University
- James Smith - Texas A&M University
- Lesley Mary Smith - George Mason University
- Sara Steger - The University of Georgia
- Gary Stringer - University of Exeter
- Patrik Svensson - Umeå University
- Melissa Terras - University College London
- Bill Turkel - University of Western Ontario
- Kirsten Uszkalo - Simon Fraser University
- Claire Warwick - University College London
- Sander Westerhout - Moore Institute, NUI Galway
- Stephen Woodruff - HATII, Universit of Glasgow
- Paul Youngman - University of North Carolina-Charlotte
- Vika Zafrin - Boston University School of Theology
- Joris J. van Zundert
Notes
Works Cited
Last updated:
Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations
Affiliated with: Literary and Linguistic Computing
Copyright 2005 -

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.