Abstract
There is an increasing use of information visualization techniques in Digital
Humanities to support the analysis of literary works. On the other hand, the rise of
digital reading on the web as well as the development of dedicated e-book readers has
triggered a variety of hardware and software solutions to provide new reading
environments and new material engagements with textual forms. In this paper, we
propose a new metaphor, In-Out-In metaphor, to support the reading of literary works
in a digital medium. Our model integrates information visualization techniques with
plain text reading into the reading flow. This approach differs from the well-known
dichotomy between close and distant reading because its emphasis is not on supporting
the analysis of the texts being read, but on providing a smooth flow between focus
and digression, which naturally occurs during a reading experience. We present a
solution to read and explore the Book of Disquiet by
Fernando Pessoa, an unfinished book composed of a set of modular texts that have been
edited in different sequences and which can be read multi-sequentially. The research
and design decisions for the visual reader of the Book of
Disquiet are meant to provide an appealing, rich and interactive online
reading experience through a web-based application, LdoD Visual. The implemented
features apply information visualization techniques with an emphasis on exploring the
modular nature of the book. Since this is a fragmentary literary work, its reading
can be fragmentary as well, but providing a smooth multiple flow reading experience.
1. Introduction
The
Book of Disquiet (LdoD, from
Livro do Desassossego, in Portuguese) by Fernando Pessoa is a
fragmentary literary work that was left unedited and unpublished by the author. In
1982, forty seven years after Pessoa’s death (1935), its first edition was published
[1]. Since then, three additional critical editions of the book have
appeared, showcasing significant disparities of interpretation about how the book
should be organized. Between 2012 and 2017, a team led by two co-authors of this
article (Manuel Portela and António Rito Silva) created the
LdoD
Archive: A Collaborative Digital Archive of the Book of Disquiet
[
Portela and Rito Silva 2017]. The
LdoD Archive can be
described as a hypermedia interactive engine that has realized the vision of an
endlessly reconfigurable book. It is both a scholarly digital edition and
meta-edition that enables users to compare each version of the
Book of Disquiet with all of the versions encoded in the archive, and a
virtual editing space designed with game-like principles for enabling different types
of users (experts, students, general readers) to make their own editions and
collections of the
Book of Disquiet. The stated aim of
this evolving archive is to experiment with computational forms of editing, reading,
and writing in ways that go beyond the bibliographic imagination [
Portela and Rito Silva 2015][
Rito Silva and Portela 2015][
Portela 2017][
Portela 2019][
Portela 2022]. The
LdoD Visual – a web application integrated into the
LdoD Archive – explores the reading flow within this
complex digital environment.
The modularity of The Book of Disquiet is, in fact, the
contingent result of material and historical features that tend to reinforce each
other: on one hand, each text is a self-contained unit that has no necessary
narrative continuity with other texts; on the other hand, there is no defined
ordering of the entire corpus of circa 600 pieces. Autograph textual units are also
in various stages of revision: first draft manuscripts, typescripts with manuscript
emendations, clean typescripts, twelve published texts. Pessoa only defined a few
textual clusters, and even those suffered changes over time during the two stages of
composition (1913-1920; 1928-1934). Given this contingent modular nature of the book,
its fragments can be read regardless of any particular order, offering the
opportunity for a fragmentary reading of the book, that is, a practice of reading
that fosters divergent reading paths that can be built by the actual reader, instead
of following a typical sequential reading that is bound to happen in a rigidly
defined story sequence.
In the
LdoD Visual, we used the particular structure and
characteristics of the
Book of Disquiet to explore, and
smoothly integrate, two current research trends in Digital Humanities: information
visualization techniques applied to texts, including the possibility of moving
between close and distant reading scales [
Jänicke et al. 2015], with the
design of web interfaces for accessing complex literary archives and the emergence of
e-books as a reading medium [
Koolen et al. 2012]. We propose a new reading
metaphor, the In-Out-In metaphor, which integrates information visualization
techniques with the plain reading of the text, to support the focus-digress flow that
structures the embodied activity of the reader. By
focus-digress flow we
mean that during the focus stage the reader is in the story, while the digress stage
corresponds to moments of self-consciousness of textual form, structure and
navigation, as well as associative thought processes, both of which interrupt
immersive reading.
We have designed and implemented a web-based application to read the
LdoD whose main objective is to give the reader a sense of
choice and an active role while reading and browsing through the book’s multiple
textual fragments, in what should be a pleasurable and immersive user experience for
both humanities researchers or just interested readers. The entire rationale of the
LdoD Archive has been to offer a multi-layered
access to the text, mediated through specific interfaces for each major function.
Interfaces should be meaningfully navigated by interactors with very different levels
of knowledge of the text – from the novice to the learner to the expert – and with
distinct aims in mind, including leisure reading, study and analysis, advanced
research, and literary creation [
Portela 2017].
To achieve this goal at the level of the reading interface, we integrate a set of
meta-information about the
Book of Disquiet with
information visualization techniques. Information visualization is a broad field that
can be applied to a large domain of different areas, providing insight based on input
data with different perspectives, summarizing relationships, identifying and
comparing patterns, trends, outliers, finding correlations, among other tasks [
Manovich 2011]. In this project, visualization has been conceived as a
humanistic interface for integrating different reading strategies and proving readers
with a perception of reading as the traversal of a semiotic space that is both
topological and semantic, and which is responsive to the readers’ agency [
Drucker 2014][
Murray 2012].
In order to integrate the existing meta-information with information visualization
techniques we developed a tool, the LdoD Visual, which
supports the exploration and pleasurable reading of the Book of
Disquiet. The implemented solution provides new contributions for the
reading and exploration of this work, in particular, and to the concept of reading
flow in Digital Humanities, in general. This tool is built on top of the Collaborative Digital Archive of the Book of Disquiet, as
mentioned. So the visual reader should be understood as a second-degree interactive
representation – i.e., an additional interface – for providing a rewarding reading
experience of a highly complex corpus of 600 texts. Its conception brings together a
metaphoric model of the reading process, on one hand, and an algorithmic and
graphical modelling of that process, on the other.
Besides describing the technical and graphical details of the
LdoD
Visual as a reading interface, this article makes three related claims.
We argue that our computational model of reading interactions is adequate for
representing the multiplicity of reading traversals inherent in the
Book of Disquiet as a modular and open network of textual
sequences. We also claim that our model of the reading flow as a recurrent process of
immersion-emersion can be equated with the networked digital medium itself, insofar
as the continuous focus on strings of text required for immersion can be smoothly
integrated with the macrotextual logic of the visualizations facilitating textual
overviews, hypertextual connections, and frame jumps. Finally, we argue that the ways
for moving into, moving within, and moving out of the text provide a satisfactory
balance involving two scales of textual representation that could be useful for other
digital humanities projects of highly complex textual corpora. We believe the
ergonomic solution embodied in our reading interface explicitly integrates close
reading, hyper-reading, and machine reading [
Hayles 2012], and thus
contributes to the design of new reading interfaces.
2. Related Work
In this section we present some background concepts regarding the LdoD Archive, Visualization in Digital Humanities, and Classification
in Digital Humanities, the three conceptual and technical contexts in which this work
was developed.
2.1. The LdoD Archive
The
LdoD Archive provides every reader with the
possibility of reading the
Book of Disquiet according
to
four expert editions: the first critical
edition, edited by Jacinto do Prado Coelho [
Coelho 1982], which was
published in 1982, as well as three critical versions that have been edited by Teresa
Sobral Cunha (1990-91 [2008] [
Sobral 2008]), Richard Zenith (1998
[2012] [
Zenith 2012]) and Jerónimo Pizarro (2010) [
Pizzaro 2010]
[2][3]. Each edition is composed
of the total number of fragments and their relative order varies from edition to
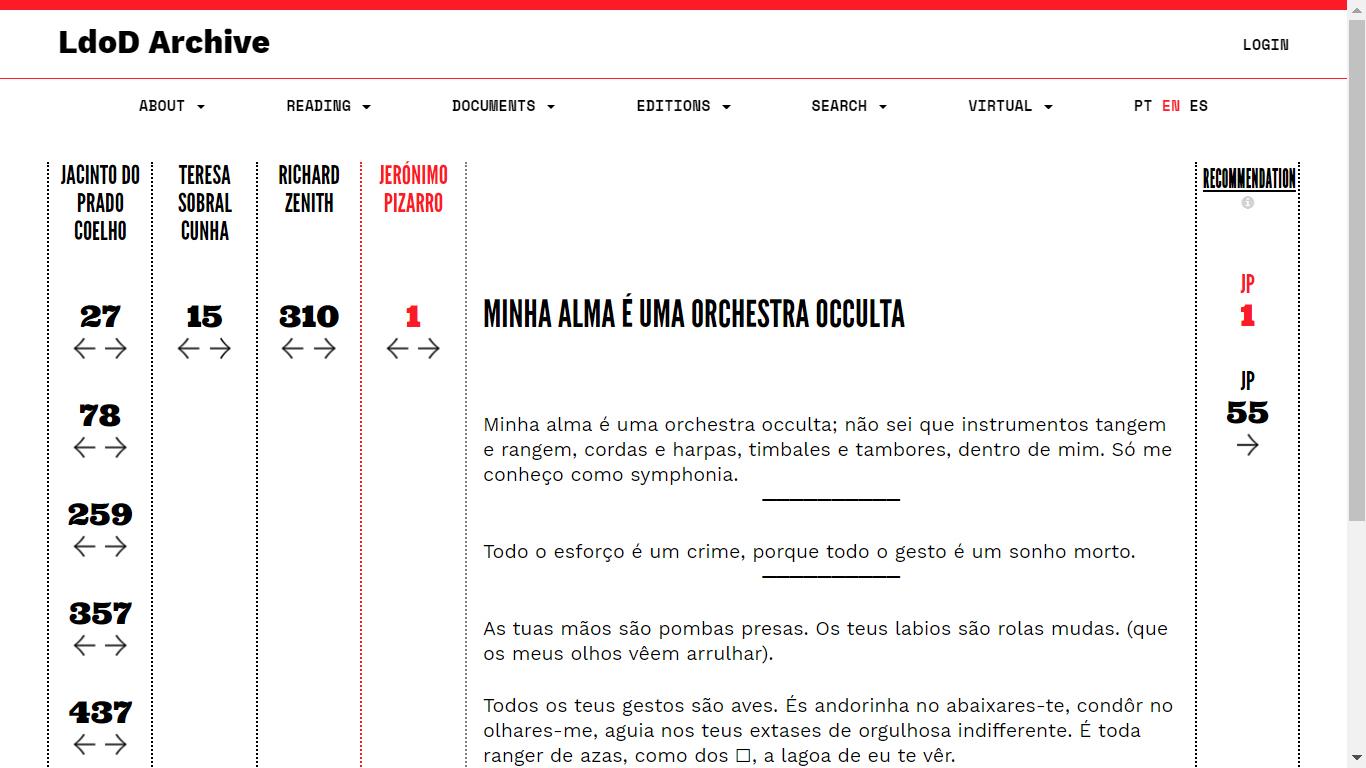
edition. In the LdoD Archive, the user can read each fragment while comparing its
respective position across these expert editions, and they can also have access to
additional information, which may also vary according to the edition, such as date
and heteronym attribution.
In the LdoD Archive, users can also create their own
virtual editions of the LdoD by selecting fragments from
each of the 4 expert editions, sorting, annotating and tagging them. This virtual
edition creation can be produced in a collaborative manner, in which case several
users are involved, and users can play the roles of editors and managers of a virtual
edition. The tagging of a fragment, which can apply to the fragment as a whole, or to
just a segment of the fragment, is done by means of a set of categories that is
associated with the virtual edition. This set of categories is designated as the
virtual edition’s taxonomy.
Each fragment has different properties, such as its title, text, date and the edition
and categories to which it belongs. There are many more features and possibilities
that can be explored in the archive, such as additional reading tools, original
documents, comparisons between textual transcriptions, fragment search, multiplayer
classification games, and the writing of variations based on the existing
fragments.
2.2. Literary Reading on the Web
Whereas hypertext structures in print books are generally subordinated to the
sequential flow of textual strings on the page (they gravitate around the text, as
table of contents, footnotes, references, etc.), hypertext structures in digital
media alter the dynamics between self-contained and associative reading, as they can
place any textual string in direct relation to a multiplicity of other texts, thus
increasing the ratio of textual interruption. Links among disparate strings of text
become much more frequent, and readers follow networks of association in interrupted
and labyrinthine traversals. With the emergence of the World Wide Web as a hypermedia
environment in the 1990s and early 2000s, the integration of verbal text into
multimodal genres of communication continued to transform our media for symbolic
production and exchange. More recently, mobile social media and the development of
smartphones as multifunctional devices further extended this general transformation
of digital literacy.
Even if visionary engineers imagined the future interface of computational devices as a
sort of augmented book (as is clear from Alan Kay’s 1972 Dynabook prototype), and
even if current electronic tablets somehow attempt to emulate the ergonomics of the
portable book, the electronic writing and reading space reconfigures and reforms the
set of relations inherited from bibliographic structures. The redesign of information
spaces of legacy print forms for the networked screens of programmable media has been
a source of continuous reflection and engineering experimentation in many areas –
from scholarly editing to commercial publishing to educational tools, particularly
since the late 1990s. These transformations have also been studied extensively, from
human-computer interaction to studies of literacy to cognitive science [
Baron 2015][
Mangen et al. 2016][
Mangen et al. 2019].
Studies seem to concur on the significance of changes to the ecology of reading
practices, and on cognitive differences in terms of orientation and comprehension.
Complex hypermedia literary archives, such as
The William Blake
Archive
[4] (under development for almost
three decades), have had to adapt to this changing ecology of the web. In those
scholarly editing projects combination of search functions, navigation structure and
reading interface has undergone several redesigns from highly hierarchical networks
of links – typical of the early hypertext remediation of bibliographic structures –
to current on-the-fly aggregations based on specific XML-encoding conventions.
Interviewed by Werner Herzog, in
Lo and Behold: Reveries of the
Connected World (2016), Ted Nelson recalls a childhood episode when he
was with his grandparents in a row boat, and, trailing his hand in the water, he
notices the water flowing around his fingers in intricate patterns of connection.
This epiphanic moment gives him awareness of the connectedness of everything which he
associates to his future vision of hypertext as a powerful open-ended
multidirectional changing system of relations among all texts and all media.
Non-sequential hyperlinked literature as an evolving network of transclusions
challenges reading practices based on linear forms of writing [
Nelson 1965][
Nelson 1995][
Nelson 2003].
Although not as flexible and unconstrained as imagined by Nelson, the current
mediascape of reading was radically transformed by hypermedia and algorithmic textual
production and analysis. Despite the early apology for the liberating, dynamic and
heterarchical potential of hypertext by literary theorists and digital writers [
Moulthrop 1991][
Bolter 2001][
Landow 2006],
research into hypertext software had always recognized the disorienting effect of
link and node structures as both a design and cognitive problem [
Theng et al. 1996][
Theng and Thimbleby 1998], to which alternative
representational and navigational forms, such as spatial hypertext, have been
proposed [
Marshall et al. 1995][
Bernstein 2011][
Solís and Ali 2011].
Almost three decades after the first literary experiments with hypermedia, Stuart
Moulthrop and Dene Grigar (
2017) have asked four
hypertext writers (Judy Malloy, John McDaid, Shelley Jackson, and William Bly) to
revisit their early work of the late 1980s and 1990s in order to recover the writing,
programming, and reading mechanics involved in their exploratory uses of specific
machines and programs, including the emerging conventions of the hyperlink as a
resource for poetic and narrative expression. Moulthrop and Grigar’s deep reading of
the works of those authors engages the multilayered nature of digital textuality,
including the ways in which hypertext and algorithmic processes affect our reading
expectations of texts as holistic self-limited entities. The elusiveness of the
textual whole is inherent in the intricate topologies created not just by
hyper-reading as an unbounded and labyrinthine traversal, but also by the factorial
virtualization of text as a responsive permutation of language bits.
Many of the same cognitive challenges of early digital genres continue to be addressed
in the design of dedicated e-book readers and in current attempts to create a
satisfactory balance between competing reading modes in digital media. Several
analyses have been done on the hardware and software features for reading in
electronic environments [
Koolen et al. 2012] that highlight the differences
between linear sequential reading and multicursal interactive reading, which are
particularly relevant in the context of academic research or education. This tension
between continuity and discontinuity pervades all solutions, in which there is a
tradeoff between the smooth flow of reading and the possibility of analysis and
inquiry about what is being read. If we think of Digital Humanities as the coming
together of digitized artifacts, digitized methods for modelling and analyzing those
artifacts, and digitized interfaces for representing those artifacts and those
analyses, then the development of reading interfaces remains an important component
in the invention of rhetorical conventions and modes of communication in networked
programmable media.
2.2.1. Reading in the LdoD Archive
Prior to this work, the
LdoD Archive provided two reading
user interfaces: one that emphasizes
comparison between editions and another that emphasizes the sequence of
reading (Figures 1 and 2).
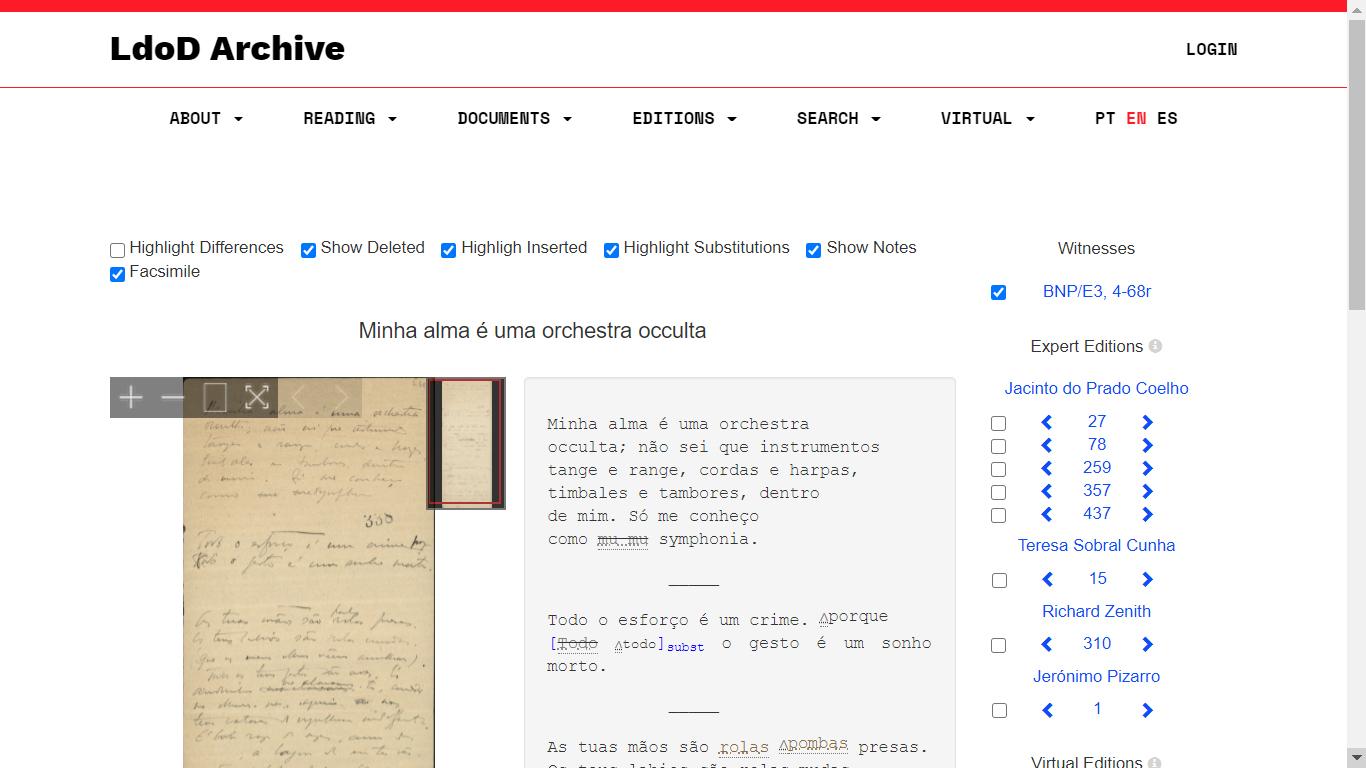
In the comparison user interface, it is possible to have a detailed highlighting of the
differences between the authorial sources and the editorial transcriptions, and also
across the editorial transcriptions themselves. It is also possible to annotate
particular texts (or textual passages) with comments and tags when specific texts are
used in the creation of a virtual edition.
The differences between transcriptions among the different expert editions, and
authorial sources, are highlighted by placing the fragments side by side, and using
colors to identify which parts differ. This user interface also allows the comparison
of meta-information assigned by the expert editors, such as title, date of
publication, heteronym attribution, page number, which can differ according to the
edition. Additionally, this interface also allows users to compare the transcription
with the original document sources, by presenting the documents’ facsimiles and
providing a diplomatic transcription, which includes deletions, insertions and
substitutions.
On the other hand, and since the LdoD Archive also
supports the definition of virtual editions, it is possible, through the comparison
user interface, to compare the differences between the fragments, in terms of the
assigned tags and annotations done. It is through the comparison interface that
authenticated users can annotate and tag the fragments.
Due to the focus of the comparison user interface on the analysis aspects, another user
interface was defined, in order to provide a smother reading experience, although
still emphasizing the comparison between the different sequences of reading the
LdoD. This interface has a look and feel closer to
the printed typography of the period the LdoD was
written, and intends to provide reading sequences according to each one of the four
expert editions. Besides, it provides a recommendation interface that suggests the
next fragment to read, given the fragment being read and a set of criteria, such as,
for instance, text similarity between fragments.
We could say that the reading interface for comparing editions is aimed at scholarly
engagements with the text, whereas the reading interface for showing divergent
reading sequences is meant for general readers. In the latter interface readers have
the option of reading vertically within a particular sequence or horizontally across
the entire corpus, thus redefining their textual traversal according to the
multicursal logic of the medium which, in turn, is critically used to explore the
modular structure of the work itself. On the other hand, the aim of the new visual
reader is to abstract textual units and their meta-information and present them
visually in ways that enhance movements within and across the text. The hypertextual
and textual dynamics of the LdoD Visual embodies an
ergonomic and cognitive model of the reading process in the design of the
interactions.
2.3. Visualization in Digital Humanities
Jänicke et al. (
2015,
2017) address visual text analysis in Digital Humanities and categorize
each of these techniques as distant reading techniques, which aim to generate an
abstract view of textual content, and as close reading techniques, which rely mainly
on annotations and the use of different colors and underlining styles to lead to a
deep comprehension and thorough interpretation of textual passages. They analyze how
close and distant reading techniques can be combined in ways that could bridge these
two perspectives so that the user can switch between close and distant reading. This
is mainly achieved by side-by-side visualizations of the text being read and its
meta-information, which make it possible to switch from a close reading of a
particular fragment to some kind of overview associated with specific metadata. On
the other hand, it is possible to access a particular text from the distant reading
view where the text is represented because it has properties that are analyzed in
that distant reading mode [
Cheema et al. 2016]. This integration between close
and distant reading is similar to our goal but our emphasis is on providing a reading
experience, while the integration of close and distant reading is concerned with the
analysis and understanding of the texts, such that close reading is frequently
related with the annotation and generation of meta-information while the user is
reading a text.
2.3.1. Visualization Techniques for LdoD
Given the specific characteristics of the LdoD we can
analyze which visualization technique can be applied in its representation. These
techniques belong to different areas and types of tasks, such as reading guidance,
user navigation, global view, and exploratory analysis.
Reading guidance features consist of giving important information for the user
regarding a specific fragment or even a collection or category of fragments, where
the focus is on the fragment that is currently being read. User navigation features
provide the user with an interface to navigate between different parts of the LdoD, in which the focus is on the relationship between
the fragment being currently read and the remaining fragments of the book. Global
view features have the objective of giving the user a summarized presentation or
zoomed-out view of content from the LdoD, thus directing
the focus to the edition that is being read. Exploratory analysis features present
the user with information that is more focused on exploring relationships in the
LdoD without necessarily converging to the task of
reading.
Word clouds [
Viégas et al. 2009][
Mohammad 2012][
Heimerl et al. 2014] can be used to provide global views and reading
guidance. Word clouds can be associated with the taxonomy categories of a virtual
edition. After being presented with a word cloud of the available categories, and
clicking on one of them, the user would be redirected to a list of fragments that
corresponds to the selected category.
Also by exploring the categories associated with the virtual editions, it is possible
to provide a global view of the edition, using colors to identify those fragments
associated with a particular category. This feature would provide a global view of
the fragments tagged with that category and the navigation to another fragment that
is associated to the same category. This visualization technique, is, for instance,
used in the Diggersdiaries web site [
Vilaplana and Pérez-Montoro 2017].
Besides the categories criterion, other criteria are supported by the
LdoD Archive, such as text and heteronym, and they can be
used to define a distance value between fragments. In this case, when reading a given
fragment, the user could browse through similar fragments according to the selected
criteria, and this relation can be visually represented using a network graph to show
how close certain fragments are in relation to others. This would provide reading
guidance. Alexander and Gleicher (
2016) make use
of network graphs to visualize text similarity between different work by William
Shakespeare.
By highlighting some of the fragments’ words according to their relevance in the
context of the entire book it is possible to provide a guidance while reading a
fragment. The weight of this highlighting could be made resorting to a metric like
Term Frequency – Inverse Document Frequency (TF-IDF)
[5]. Text Skimming [
Brath and Ebad 2014][
Brath and Ebad 2015] is a technique used in knowledge
maps and to support reading and it can also be applied in this context.
There are some differences between the experience of reading a book on a browser or
other portable virtual book readers and the actual physical book. In an attempt to
close this gap, it would be interesting to provide the user with a graphical
representation that makes the awareness of where the actual reading fragment is
placed in the current edition. This type of feature belongs to the global view
area.
2.4. Text Classification
The visualization techniques are built on top of the information to be presented plus
some meta-information. In the context of the LdoD
Archive, the information is the fragment transcription and its position
in an edition, and the meta-information is the date, heteronym and categories
assigned to a fragment. Additionally, some meta-information is generated from the
fragment through the TF-IDF associated with it, by considering each fragment as a
document and the words in the fragment its set of terms.
2.4.1.Distance Measures in the LdoD Archive
The
LdoD Archive implements a set of measures to calculate
the distance between two fragments belonging to the same edition according to four
types of meta-information: date, heteronym, categories, and TF-IDF. The distance
between two fragments is calculated using the cosine similarity [
Singhal 2001], according to which a vector is defined for each of the
fragments to be compared.
[6]Associated with the heteronym, a vector of two cells is defined, one for each
heteronym, Vicente Guedes and Bernardo Soares, in which the value 1.0 is assigned to
the cell of the heteronym if the fragment is assigned by the editors to it.
For the date, a vector is defined with the number of cells equal to 1934-1913+1, which
corresponds to the period when the fragments were written. For the cell corresponding
to the year when a fragment was written, the value 1.0 is assigned and for the other
cells a decay of MAX(0.0, 1.0 - N x 0.1) is applied where N is the distance between
the year associated with the cell and the closest cell with value 1.0.
For the text, the set of the first 100 TF-IDF terms associated with each one of the
fragments that we intend to compare is calculated. Note that this set is between 100,
in which the two fragments have the same first TF-IDF 100 terms, and 200, in which
all terms are different. Then, for each fragment, a vector whose size equals the
number of terms in the set is defined, and to the cell associated with a term the
value 1.0 is assigned if the term belongs to the first 100 TF-IDF terms of the
fragment, and 0.0 otherwise.
To calculate the distance between two fragments using the set of categories assigned to
them a vector whose size is equal to the number of categories associated with the
virtual edition taxonomy is defined. Then, for each fragment, its respective vector
is filled with 1.0 for the cells corresponding to the categories the fragment has,
and 0.0 for the other cells.
Note that the archive also uses a topic modelling algorithm, through the Mallet
software
[7], which allows
the virtual editions to be automatically classified using the set of generated
topics.
3. The In-Out-In Metaphor
Reading a book is a task in which the reader constantly switches between two states of
focus. The reader is either completely engaged in the reading task or briefly
disengages out of the act for various reasons. These moments of disengagement can be
triggered, for example, by recalling what happened in previous chapters, picturing a
description of a character or scenario, remembering a similar personal experience in
relation to what has been read, linking a new event to what has happened in the past
or even trying to make a prediction out of it, among other possibilities. Immersion
can also be interrupted by the readers’ self- awareness of form, structure and
navigation. The in-moment represents the state of being inside the textual world,
absorbed by its signifying chain. The out-moment points to the liminal state of being
outside the text, a liminality that is a function of the text itself and the ways in
which it draws attention to its materiality or generates mental processes of
association and reflection.
Part of our solution model revolves around this phenomenon, as it is intended to
materialize and direct this constant in and out that happens while emerging out of
and submerging into the source text. It is important to highlight that, in comparison
to a typical book where we have a rigidly defined story sequence, the LdoD is a fragmentary literary work. This means that these
moments of disengagement can turn into a chance for the user to reposition herself in
another part of the book. This nuance leads to a reading path and global mental
picture of the world created by the book that can greatly vary from reader to reader,
opening up space for providing the user with an immersive experience in which she can
have a sense of choice and an active role while reading the LdoD. If we consider that genre is an emergent property that results
from specific arrangements of textual units, readers of the Book
of Disquiet - mediated by this in-out-in visual reader – may even
experience the oscillation between fictional autobiography and fragmentary narrative
as an effect of their traversals. The emergence of a variable textual whole becomes a
function of their reading acts. Self-contained textual units, when traversed as
reading text, correspond to the in-movement, but when navigated as visual
representations correspond to the out-movement.
4. The LdoD Visual
The solution’s interface is composed of a group of different main menus: edition
selection, reading, current user activity, new user activity, and reading history
menus. Before describing each menu in detail, it is important to explain the concepts
that will be used throughout this solution proposal.
4.1. Core Concepts
An information visualization technique, among other descriptions in
previous sections, is a visual representation or metaphor that can provide insight
and different perspectives about almost any type of input data, as we saw above from
the multiple examples given in the related work applied to the context of the Book of Disquiet.
Semantic criteria is the set of attributes that can be encoded in the
information visualization techniques in the context of the Book
of Disquiet, namely word frequency, word relevance (TF-IDF),
chronological order, heteronyms, fragment categories, and taxonomies. Text similarity
is another semantic criterion that can be derived from word frequency and word
relevance.
A user activity is an activity that can be selected by the user while
reading a fragment from the Book of Disquiet, consisting
of making use of an information visualization technique to encode
different semantic criteria. An example of a user activity is “Find similar fragments by text similarity” to find
fragments that are similar to the fragment that is currently being accessed, using a
network graph as the information visualization technique that encodes text similarity
- the semantic criterion that is chosen by the user while selecting the new user
activity. To achieve an intuitive and easy-to-use solution, independently of the user
activity's information visualization technique and encoded semantic criteria, the
user selects a user activity by clicking on a button with a high-level description of
what the user activity was designed to achieve, e.g. “Find
similar fragments by text similarity”.
A reading flow is a sequence of accesses, done by a single user, such that
the user progresses in the sequence of fragments through in-in, in-out-in and
in-out-out-in subflows. An in-in subflow corresponds
to a situation when the user is accessing a fragment and accesses another fragment,
for instance, by switching to the previous page. This switch is done according to the
semantic criteria the user chose for accessing the fragment,
defined by the current user activity. For instance, if the semantic criteria
correspond to the set of fragments of a given category, the reader will access
another fragment belonging to the same category. An in-out-in subflow
corresponds to a situation in which the user is accessing a fragment, moves to the
current user activity menu (to be described in the next subsections) in which the
reader has a complete view of the fragments according to the same semantic criteria
used to access the fragment being read. For instance, if we consider the previous
example, the complete view may show all fragments that have the same category in the
context of all fragments. An in-out-out-in subflow corresponds to a
situation when the reader stops reading, according to the current user activity, and
chooses a new user activity in which she continues to read.
Overall, the reading flow corresponds to the implementation of the in-out
metaphor, where the level of disruption is minimal in in-in subflows,
and maximal in in-out-out-in subflows. Note that to reduce the
disruption of the reading flow, all changes can be done using shortcuts, pressing a
single key, and most menu elements fade-out in the reading interface when the reader
does not use the mouse so that the screen only contains the text of the fragment.
4.2. User Interface Structure: Menus and Navigation
In the context of an edition, the LdoD Visual has three
main types of elements: selection menus, reading view, and global views.
4.2.1. User Activity Selection Menu
Once a context of an edition and one of its fragments is chosen, the main selection
menu allows users to choose between the available user activities, given the context,
and access the corresponding global view. The user activities are ordered by semantic
criteria: edition order, chronological order, text similarity, categories/taxonomy,
and heteronym.
As shown in Figure 3, each user activity is represented by a card with a title, a
button with the corresponding keyboard shortcut between straight parentheses that
will take the user to the activity, and an image that represents the information
visualization technique for that user activity, which can also be clicked to access
the user activity.
The image and button will be greyed out if the activity is unavailable - for example,
if the currently selected edition has no taxonomy, user activities that use this
semantic criteria category will not be available, displaying a message explaining why
it is not available in the title and its selection button is also unavailable.
The same semantic criteria can be used with different information visualization
techniques. In Figure 3, we can observe that the top 2nd
and bottom 1st cards use different information
visualization techniques for chronological order, respectively, custom square map and
timeline; the top 3rd, bottom 3rd and 4th cards use the semantic criteria
associated with the taxonomies, where top and bottom 3rd
use the same information visualization technique, word cloud, the former in the
context of the selected edition, and the latter in the context of the selected
fragment; while the bottom 4th uses a different
visualization technique, network graph.
4.2.2. Reading View
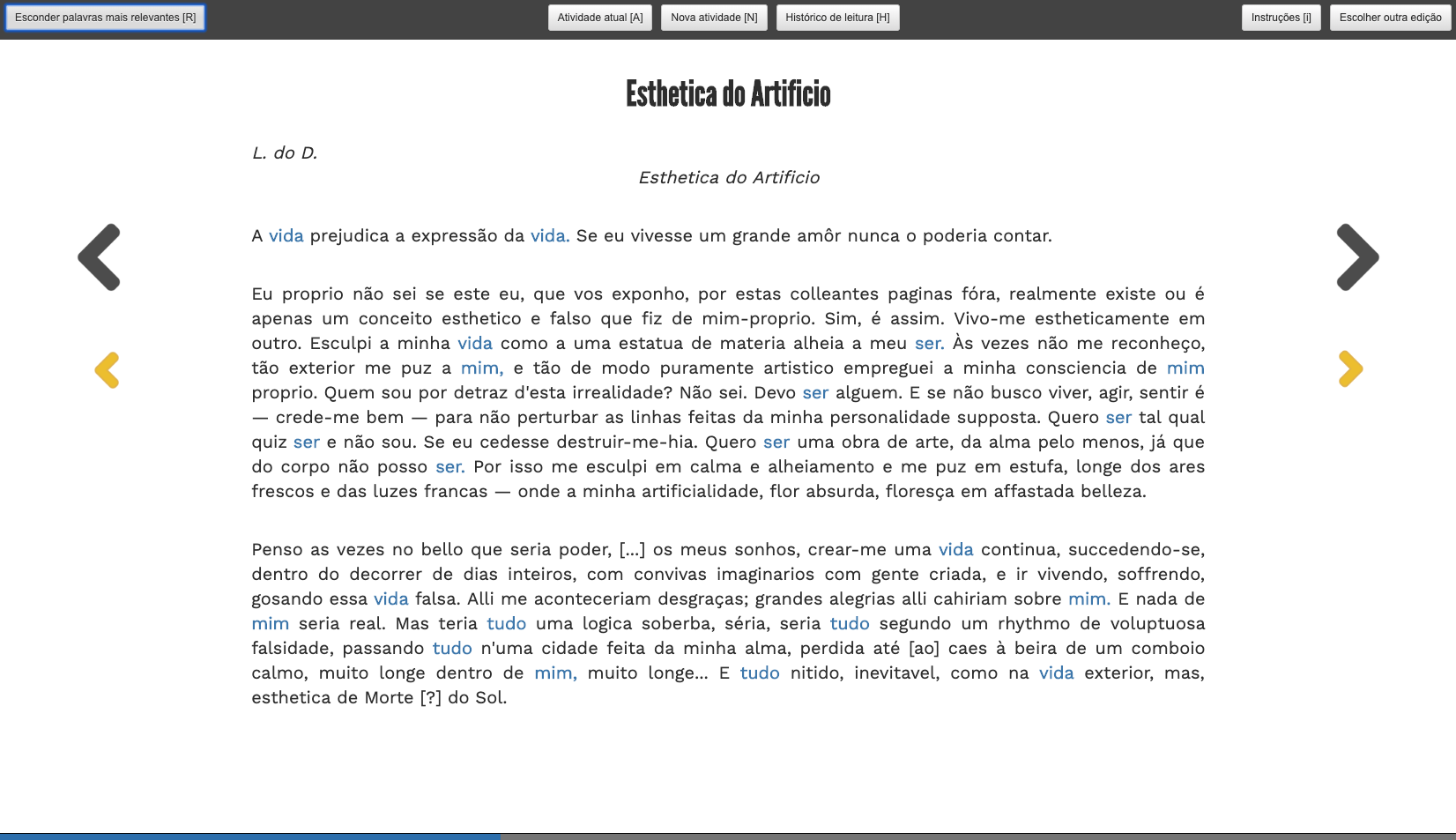
In this view, the focus is on reading the text of a selected fragment, as represented
in Figure 4, where the fragment title and text are presented with a reading progress
bar. Since the text will be read on a screen, the used text font is a sans serif
font. The fragment title font and text font are the same ones used in one of the
LdoD Archive reading interfaces.
Besides the progress reading bar, the reading view features some elements of
established browser book readers (see Figure 5). There are previous/next fragment
arrow buttons that retreat/advance through the selected edition fragments depending
on the currently selected edition. It also allows users to navigate between fragments
according to the user selected category or heteronym, using the yellow arrows. There
are some detail features, such as smooth animation between fragment change and smooth
page scroll back to the top for the same matter. This smooth page scroll can also be
triggered by clicking on its matching button or pressing “T” on
the keyboard.
When the user stays inactive for more than 3 seconds, everything in this menu
disappears with the exception of the reading progress bar and the fragment's title
and text, as shown in Figure 4. Inactivity is timed when the user is not interacting
with any button, progress bar or previous/next fragment arrow buttons. It is then
possible to trigger everything to appear again by doing a mouse hover on any of these
elements of the menu. When the user scrolls down the page and the top buttons overlap
the text, there is also a transparency trigger. These features are activated as an
effort to maximize the user focus on reading the text and are another extra step
towards achieving our metaphor implementation.
In this menu, there is a user activity "under the hood" in the sense that it resembles
a user activity that does not break the reading flow: by clicking on the matching
button (“Highlight the most relevant words”), left button on top
(shortcut [R]), the 4 most relevant words are highlighted in blue, as presented in
Figure 5. This number was decided after extensive experimentation and fine tuning,
trying to find a balance between actual relevant content highlighting and not
highlighting too many words to the point it becomes irrelevant to do so. This option
makes use of an information visualization technique - text skimming - to encode a
semantic criterion - word relevance (more specifically, TF-IDF) -, even though it is
not described as a user activity in the sense that it can be applied independently of
what is the current user’s activity.
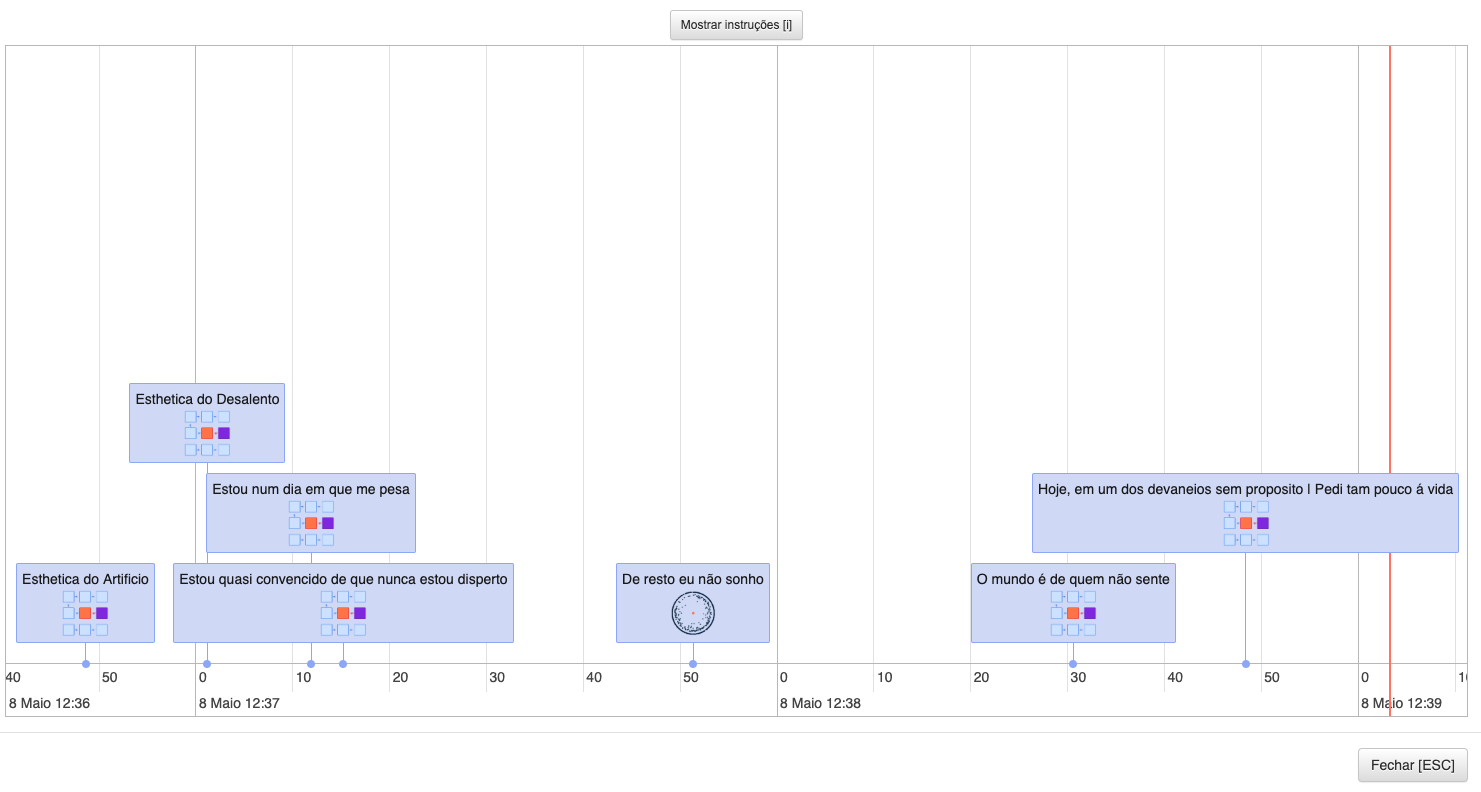
The reader can also see his/her own history of reading by pressing the button on the
right in the group of three buttons on top (shortcut [H]), as presented in Figure
6.
In this view, the reader is presented with an interactive timeline that displays the
fragments that have been read for the currently selected edition. Each history entry
is a fragment, displaying its title and a thumbnail that represents the information
visualization technique of the user activity through which that fragment was reached.
Besides, having a similar interaction to the user activity that makes use of the
timeline in the global view, the user can navigate back to a given fragment that was
previously read by clicking on its entry.
The buttons on top right, Figure 5, allow the user to see the instructions for this
menu and select another edition. The two first buttons in the group of three buttons
allow the user to access the global view associated with the currently selected user
activity (shortcut [A]) and to navigate to the new user activity selection menu
(shortcut [N]).
4.2.3. Global Views
The global views correspond to the out phase of the metaphor and are a
combination of semantic criteria with an information visualization technique. In the
following subsections we show how the global views are presented in the LdoD Visual in the context of the various information
visualization techniques.
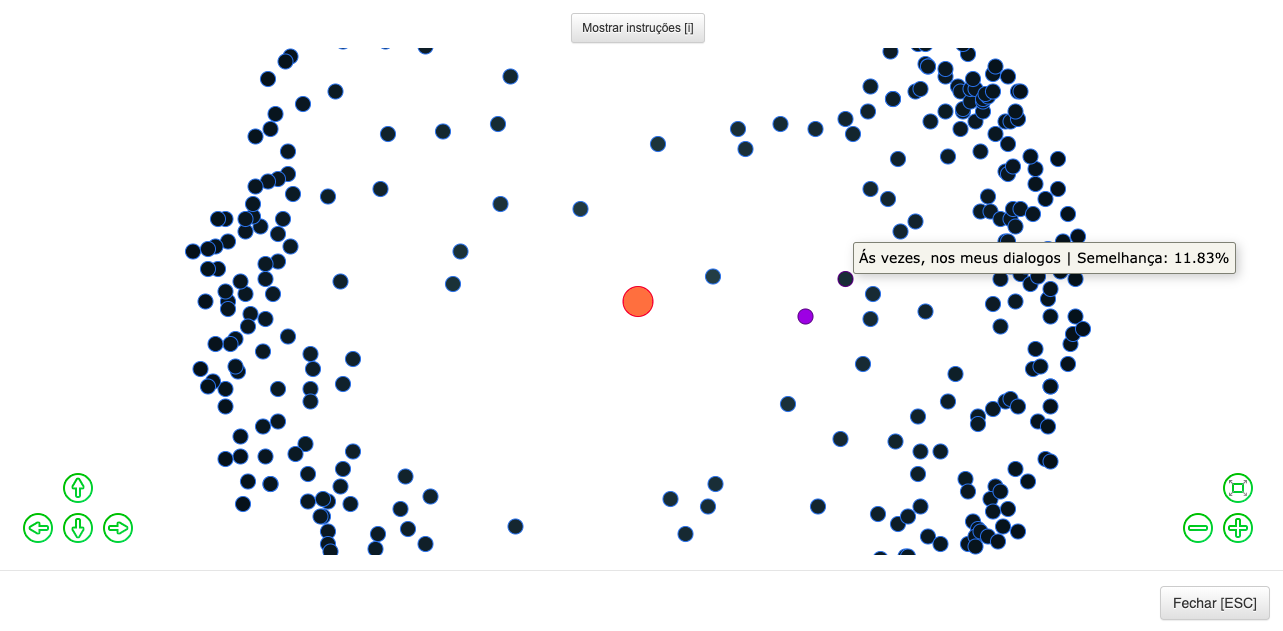
4.2.3.1. Network Graph
This information visualization technique consists of a network graph with hidden edges,
as shown in Figure 7. Each node is a circle that represents a fragment from the
currently selected edition. If the user clicks on a circle, she will be taken back to
the Reading Menu with the corresponding fragment of that
circle open to be read.
When accessing the view, the central orange circle represents the fragment in whose
context the user activity was started, and the purple circle represents the fragment
being currently read. This strategy was adopted so that the reading occurring during
a user activity is contextualized by the initially read fragment. The blue circles
represent the other fragments from the edition, and their relative distance to the
central circle expresses the encoded semantic criterion.
The user can put the mouse cursor over the circle so that a label is displayed,
showcasing the title and the value of similarity in percentage. Besides being able to
drag and zoom the network graph using the mouse pointer and mouse wheel, the user can
also use the green navigation buttons to drag, re-size, zoom in and out of the
network graph. This information visualization technique is used to encode similarity
by text and taxonomy, which in the case of Figure 7 is by text.
4.2.3.2. Word Cloud
Word clouds are used to encode semantic criteria associated with the categories of a
certain fragment or taxonomy (group of categories) of the selected edition, as shown
in Figure 8. It displays each category using different colors and the font size
varies according to the number of fragments that belong to that category.
The Word Cloud, and its semantic criteria, can be applied in two cases: (1) the set of
categories of the taxonomy of an edition, which corresponds to the case presented in
Figure 8; (2) the categories of the current fragment. In both cases, by selecting one
of the categories, the user is redirected to a custom squares map that highlights the
fragments of the select category, as described in the next subsection.
Heimerl et al. (
2014) developed a system that uses
word clouds as its central visualization method for interactive text analysis. Its
results showed that even though word clouds are aesthetically pleasing with its words
disposed in different angles, users do not find them very functional and easy to use.
Thus, results showed that participants preferred sequential layouts, where words are
placed horizontally without any kind of inclination or angles for aesthetic purposes.
For this reason, we decided to follow the same layout in the
LdoD Visual.
4.2.3.3. Custom Squares Map
This information visualization technique consists of squares linked by arrows, as shown
in Figure 9. It is similar to the network graph if we picture the squares as nodes
and the arrows as edges. Likewise, each square represents a fragment from the
currently selected edition. This group of squares linked by arrows offers a global
view of the currently selected edition, and suggests a certain order derived from the
arrows. This order depends on the encoded criterion. Each square's color and
highlighting also depends on the encoded criterion. Similarly to network graphs,
there is a special color highlighting for each square. The orange square corresponds
to the fragment where the user activity was initiated, and the purple square to the
fragment currently being read.
This information visualization technique is used to encode the following semantic
criteria:
- Edition order. Fragment squares are sorted by order of the
currently selected edition. If the user places the mouse cursor over a square,
it will display a label with the fragment title and its position in the edition,
almost as if it were a page number. This global view allows users to explore the
order of the fragments in the edition.
- Chronological order. Fragment squares are sorted by the date in
which they were written. Each square displays a two-digit number that represents
the year from that date - for example, a fragment from 1927 will have its
corresponding square with the number 27. Fragments without date have their
corresponding squares greyed out. If the user places the mouse cursor over a
square, a label will be displayed containing the fragment title and its date.
This global view allows users to explore the edition ordered by date.
- Categories/taxonomy. Fragments are displayed exactly as if the
semantic criterion was the edition's order, with the addition of highlighting in
yellow the squares of the fragments from the selected category. If the user
places the mouse cursor over a square, a label will be displayed with the
fragment title and the categories to which it belongs, as shown in Figure 9. As
previously described, smaller yellow previous/next fragment arrow buttons will
appear under the black previous/next buttons in the reading menu.
- Heteronym. It has the same behaviour as the categories/taxonomy
semantic criteria, but it highlights in yellow the squares of the fragments that
were assigned to a specific heteronym. The yellow arrow buttons are used to move
exclusively to the previous/next fragment belonging to the selected heteronym.
The global view allows users to explore the fragments assigned to a particular
heteronym.
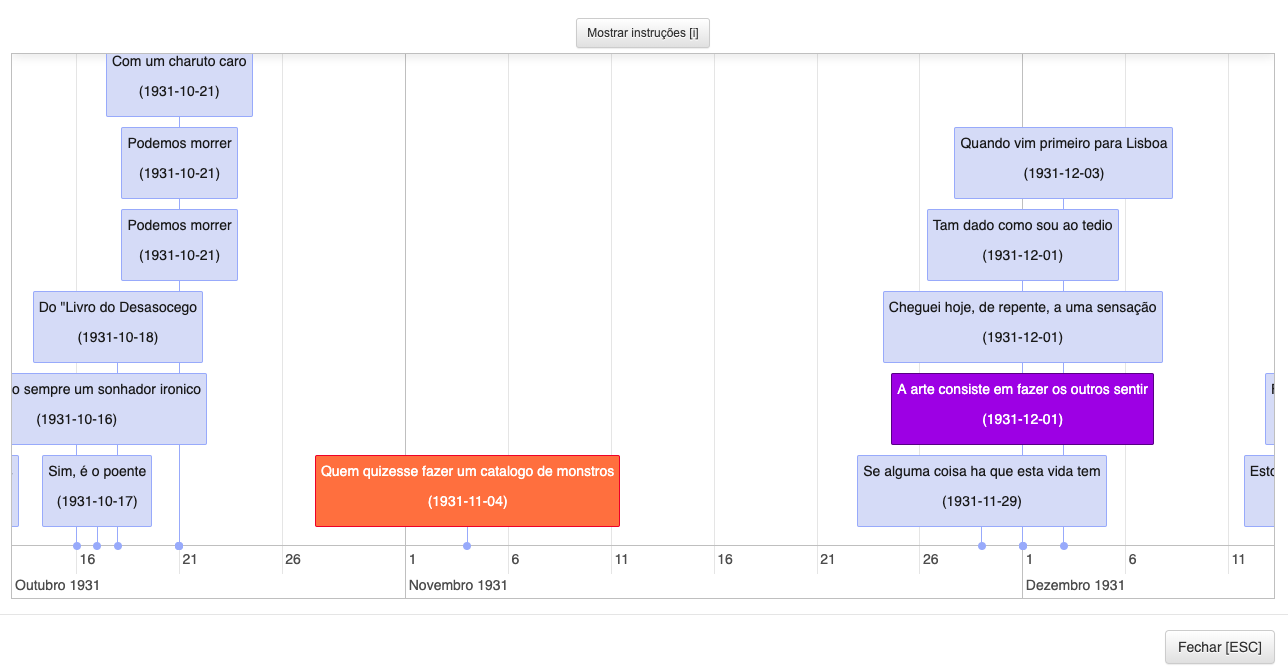
4.2.3.4. Timeline
This information visualization technique consists of an interactive timeline, in which
the user is presented with the timeline centered on the time window around the
currently selected fragment, as shown in Figure 10.
There is only one global view that uses this information visualization technique to
encode the chronological order as the semantic criterion, in order to explore the
fragments around the date of the current fragment. Each timeline entry represents a
fragment from the currently selected edition. Being consistent with the color scheme
for other visualizations, an entry will be orange if it represents the fragment that
was initially selected in the context of the user activity, and purple if it is the
fragment currently being read. The user can navigate to a certain fragment by
clicking on its entry.
5. Results and Discussion
The evaluation of the LdoD Visual was done by two types of
tests: usability tests, which assess the system’s usability, independently of the its
particular purpose; and, utility tests, which assess the quality of the system,
considering its purpose as a reading tool for the Book of
Disquiet.
5.1. Usability Tests
To assess how usable, efficient and satisfying the interaction with the LdoD Visual is, we have performed tests with 11 volunteer
users who have no expert knowledge on the LdoD Archive
and on the Book of Disquiet. The results of this type of
test are objective and quantitative.
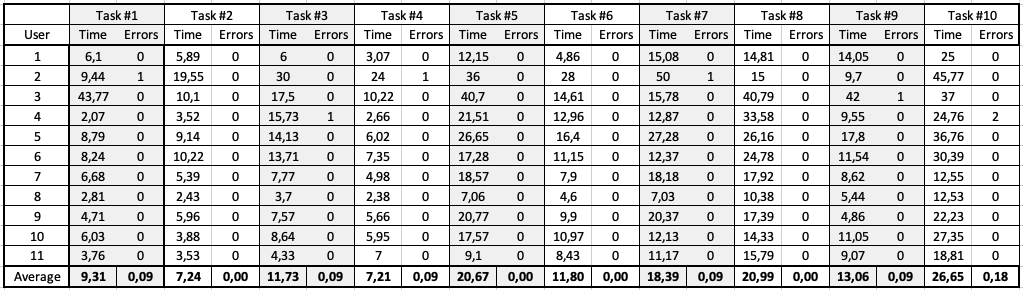
Each usability test consisted of 4 stages:
- Introduce the user to the LdoD Visual's concepts
and briefly demonstrate the system in about 5 minutes;
- Let the user explore the system freely for about 5 minutes;
- Ask the user to execute 10 tasks;
- Ask the user to fill and submit a SUS (system usability scale)
questionnaire.
In the third stage, for each task, we counted the number of errors and time taken to
complete the task. The tasks assess the usability and intuition of the user
activities' interaction with the information visualization techniques in order to
explore and navigate through the fragments from the selected editions. For instance,
to select any fragment from an edition, select the user activity that makes use of
the squares map encoding the edition's order, choose the first fragment, highlight
the most relevant words and say out loud what are the most relevant words of the
selected fragment, which was, actually, task 9.
These tasks were always executed in the same order for each user, exactly from the same
menus.
Figure 11 presents the results from which we conclude that, on average, every task was
completed without exceeding the expected time and with basically no errors, with the
exception of the last task, which was more difficult. Task 10 was conceived to
confirm if users understood why a user activity was not available for certain
fragments and what they should do in order to select other fragments that supported
that previously unavailable user activity. This was the most complex task, which
explains why it took the most time out of all tasks, even though most users ended up
figuring out what they had to do.
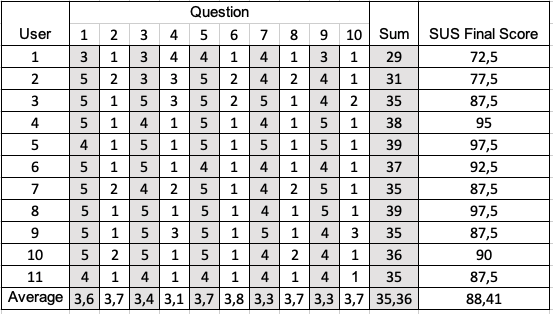
For the fourth stage, the users filled and submitted a SUS (system usability scale)
questionnaire. This is a quick questionnaire that is commonly used to figure out if
any aspect was not considered by the tests. This questionnaire involved 10 statements
for the user to answer how much he would agree with each one of them in a scale from
1 (completely disagree) to 5 (completely agree):
- I think I would like to use the LdoD Visual
regularly.
- I think the LdoD Visual was unnecessarily
complex.
- I think the LdoD Visual was easy to use.
- I think I would need help from a person with technical knowledge to use the
LdoD Visual.
- I think that all of the LdoD Visual features were
well integrated.
- I think the LdoD Visual shows a lot of
inconsistency.
- I think people will learn how to use the LdoD
Visual easily.
- I think the LdoD Visual was very confusing to
use.
- I felt confident while using the LdoD
Visual
- I needed to learn a lot of new things before I could use LdoD Visual.
The score of the SUS questionnaire is obtained by transforming the 1 to 5 scale in a 0
to 4 scale, and converting the values to be consistent, e.g., the odd-number
questions express a positive opinion and even-number questions express a negative
opinion. Figure 12 presents the results, where the questions' answer values are as
given by the subjects, and the sums, averages and SUS final scores are calculated on
the converted values.
Analyzing the SUS score, we can observe that the lowest scoring answer is number 4,
I think I would need help from a person with technical knowledge to use
LdoD Visual. This makes sense as the LdoD
Visual is relatively complex to users that have no experience with the
Book of Disquiet and the LdoD
Archive, which is the case of the participants. Regarding the final
score, when a system scores a SUS score of 80.3 or more, it is considered to be in
the top 10% of scores and the testing users are more likely to recommend it to
others. This means that if we are considering a SUS scale, the LdoD Visual is a system with good usability, having a SUS score of
88.41.
Besides these 10 SUS questions, we also added questions in order to know about the
users. In terms of the characterization of the usability test participants: 9.1%
where younger than 18, 36.4% between 18-24, 45.5% between 25-34, and 9.1% between
45-54; and 9,1% have secondary education, 45.5% have a bachelor degree, and 45.5% a
master degree. Most users had already used other software to read books in the past
and most users had not read the Book of Disquiet. It is
also possible to observe that most users strongly agreed that they would have a good
reading experience using the LdoD Visual.
5.2. Utility Tests
The purpose of the utility tests is to obtain information about the utility and quality
of the experience while using the system. These tests are important in the sense they
allow us to assess subjective and qualitative aspects of the LdoD Visual, which are difficult to be measured quantitatively.
The tests were done with 3 users that have expert knowledge about the Book of Disquiet and the LdoD
Archive. The user of the first case study is a postdoctoral researcher
with a PhD thesis on the Book of Disquiet. This user has
also worked, between 2012 and 2015, with the XML encoding of the fragments for the
LdoD Archive. The user of the second case study is
a PhD student from the PhD Program in Materialities of Literature, which is a
doctoral program that addresses the material and technological mediations of literary
practices. One of its research fields is digital humanities. This user has a BA and
an MA in graphic design. The user of the third case study is another PhD student from
the same PhD Program, who has a BA in graphic design, and an MA in Semiotics. This
user is interested in the aspects of usability of the LdoD
Archive since her PhD project involves creative practices through the
situated use of the archive. She is one of LdoD
Archive's most regular users and has been organizing a plan of activities to
teach LdoD Archive's users how to use it and fully
explore its various functionalities, including the creation of virtual editions.
The protocol for this type of testing is more flexible in comparison to the usability
tests' protocol. The users were contacted by email, introduced to the LdoD Visual metaphor, and encouraged to explore the system
before we had our actual meeting to do the case study.
During the case study the users were encouraged to use the LdoD
Visual while “thinking out loud”. We asked them
several questions regarding the real utility, potential and reading experience that
they thought the LdoD Visual provides. We also asked
them about the differences they felt as more important, in comparison to other tools
and electronic readers available, as well as comparing the reading experience of the
LdoD Visual to the other reading features available
in the LdoD Archive.
Considering the feedback received from these case studies, we can conclude that the
reception of the LdoD Visual is positive, both in terms
of concept, execution and utility. The users liked the approach on how to read a
book. They thought that it is a good match for the fragmentary nature of the Book of Disquiet. The attempt to output a visual
representation of the editions and fragments brings a new perspective on how to read
and explore the Book of Disquiet and use the LdoD Archive, highlighting its relevance for the field of
digital humanities.
The second user also described her experience with user activities in a way that
suggested that the LdoD Visual's metaphor is
successfully implemented. She stated: “The real reading
customization strength comes from the activities around the currently selected
fragment. If the reader stops and tries, for example, to continue her reading
path with a user activity that is related with reading similar fragments by text
to the currently selected fragment, there is already a reflexive question that
is specific to the reader and the navigation method centered around the selected
fragment becomes the medium for the user to be able to read around an idea that
is interesting to her. In LdoD Visual, the reader
is able to navigate through the fragments according to what is desired, having a
visual reference of the type of navigation and exploration that is being
performed in the Book of Disquiet.”
The users also suggested that the LdoD Visual is
relatively complex and that there should exist more ways of welcoming non-expert
users who are not aware of the problem and structure of the Book
of Disquiet and the the LdoD Archive, such
as "selling the concept" both as a ludic and research tool, and showcasing the
different uses and possibilities in videos scattered around the application. The
users also acknowledged the potential of the LdoD Visual
concepts such that they could be developed and expanded to explore other alternatives
of interaction with the Book of Disquiet. We could
observe that each user spent time with different parts and user activities of the
LdoD Visual. Our analysis on this is that the
LdoD Visual seems to provide different affordances
for different users, and that the objective of customizing the exploration and
reading experience of theBook of Disquiet was met.
We can also conclude that the LdoD Visual is a tool that
mainly scripts two different reading behaviours: the possibility of navigating
through the Book of Disquiet with a focus on the
pleasurable assisted user-driven reading experience, geared towards a continuous and
immersive flow; and the possibility of navigating with a humanities researcher
mindset, finding patterns, correlations and textual data insights, according to a
discontinuous and interruptive logic. Both of these reading practices are possible
resorting to the same mechanisms and representational strategies, i.e., the user
activities' information visualization techniques, even though the first type of
reading practice is the main focus of the LdoD
Visual.
6. Conclusion
The Book of Disquiet by Fernando Pessoa is an unfinished
book that can be read in any order. The modular nature of this fragmentary literary
work brings endless possibilities on how it can be traversed.The goal of this work
was to design and implement a web-based application to read The
Book of Disquiet, giving the reader an active role while reading and
browsing through the book's different fragments, defining user activities that make
use of information visualization techniques to encode different semantic
criteria.
In order to achieve this, we researched on the use of information visualization
techniques applied to textual data and literature, and on the concept and tools for
e-books and web-based reading. Afterwards, we defined the in-out-in
metaphor that was used as the guiding concept for whether or not a certain
architecture or feature choice met the objectives and served the overall purpose of
this work.
According to this metaphor, we defined the user activity concept, which establishes a
perspective on how to read the book. A user activity is a combination of an
information visualization technique with a semantic criterion, where the latter is
used to classify the fragments and the former to visualize them according to the
classification. The solution architecture considers three types of user interfaces: a
user interface in which the user activity is selected; a global view in which the
fragments are visualized according to the chosen user activity; and a reading view to
support the reading and navigation between fragments, according to the chosen
semantic criteria.
The final system was tested for usability and utility, and it got positive feedback
from both non-expert and expert users of the Book of Disquiet
and the LdoD Archive. The usability tests have
shown that it is possible to complete the defined tasks in the expected time and
without errors, and the utility tests also confirmed that the proposed metaphor meets
the experts’ vision of the book and how to explore its multiple paths of reading.
As a web-based application for exploring the process of reading, the
LdoD Visual contains several features that correspond to
what the
LdoD Archive describes as “the
simulation principle,” that is, the ability to provide interactors
with a reflexive engagement with the textual environment [
Portela and Magalhães 2020]. Through a recursive process of going into the text and coming out of the text,
readers are able to explore the
Book of Disquiet as a
particular kind of reading experience and they are also able to see how their acts of
engaging with the text become registered in the visualizations. The implemented
visualization techniques thus bring together the modularization of the text and the
modularization of the reading of the text.
The LdoD Visual is a tool that has the potential to grow
and become an improved version of what it already accomplishes. One major improvement
would be the possibility of saving the reading history state to a user account,
preferably in the LdoD Archive. This would be a logical
extension since the process of reading a book can take days, weeks or months. Another
improvement would be developing a feature to generate new virtual editions according
to specific reading paths. This would explore the LdoD
Archive goal of fostering the construction of new virtual editions of
the Book of Disquiet. In its reflexive graphical
representation of reading activities, this visual reader contributes to the
experimental textual rationale of the LdoD Archive.
We believe the In-Out-In metaphor adopted in this project can also be used as a
conceptual design tool for modelling reading processes in digital media. The design
of interfaces for complex archives of literary materials based on this model would
have twofold benefits: limiting hypertextual disorientation, on one hand, and
supporting a meaningful transition between human and machine reading processes, on
the other, for both general and expert readers. In this light, the model of the
reading flow embodied in the LdoD Visual could also be
seen as a prototype of a specifically digital paratextual apparatus for the smooth
and optimal integration of close reading and distant reading modes through multiple
visualization techniques.
NOTE: In order to keep track of the project’s evolution, the source code is publicly
available in a GitHub repository
https://github.com/socialsoftware/edition.
Acknowledgements
The authors wish to thank the anonymous reviewers of this article for their invaluable
comments and suggestions.
This work was supported by national funds through FCT, Fundação para a Ciência e a
Tecnologia, under projects UIDB/50021/2020 and UIDB/00759/2020.
Works Cited
Alexander and Gleicher 2016 Alexander, Eric, and
Michael Gleicher (2016). “Task-driven comparison of topic models.
IEEE Transactions on Visualization and Computer Graphics.” 22(1),
320–329.
Baron 2015 Baron, Naomi (2015). Words Onscreen: The Fate of Reading in a Digital World. Oxford: Oxford
University Press.
Bernstein 2011 Bernstein, Mark (2011). “Can We Talk about Spatial Hypertext?”
HT '11: Proceedings of the 22nd ACM conference on Hypertext and
hypermedia, June 2011, 103–112.
https://doi.org/10.1145/1995966.1995983
Bolter 2001 Bolter, Jay David (2001). Writing Space: The Computer, Hypertext, and the History of
Writing. London: Routledge [2nd ed.].
Brath and Ebad 2014 Brath, Richard, and Ebad Banissi
(2014). “Using font attributes in knowledge maps and information
retrieval.”
Proceedings of the First Workshop on Knowledge Maps and
Information Retrieval (KMIR 2014)co-located with
International Conference on Digital Libraries (DL 2014), 23–30.
Brath and Ebad 2015 Brath, Richard, and Ebad Banissi
(2015). “Using text in visualizations for micro/macro
readings.” 4th Workshop on Visual Text Analytics. ACM, 2015.
Cheema et al. 2016 Cheema, Muhammad Faisal, Stefan
Jänicke, Gerik Scheuermann (2016). “AnnotateVis: Combining
Traditional Close Reading with Visual Text Analysis.” Workshop on
Visualization for the Digital Humanities, IEEE VIS 2016, Baltimore, Maryland, USA,
October 24th, 2016. URL:
http://www.informatik.uni-leipzig.de/~stjaenicke/annotatevis.pdf
Coelho 1982 Coelho, Jacinto do Prado, ed. 1982. Fernando
Pessoa, Livro do Desassossego por Bernardo Soares.
Collection and transcription by Maria Aliete Galhoz and Teresa Sobral Cunha. Lisboa:
Ática, 1982. 2 vols.
Drucker 2014 Drucker, Johanna (2014). Graphesis: Visual Forms of Knowledge Production,
Cambridge, MA: Harvard University Press.
Eaves et al. 1996-2021 Eaves, Morris, Robert N. Essick,
and Joseph Viscomi, eds. (1996-2021). The William Blake
Archive. Chapel Hill, NC: University of North Carolina at Chapel
Hill.
Hayles 2012 Hayles, N. Katherine (2012). How We Think: Digital Media and Contemporary
Technogenesis. Chicago: The University of Chicago Press.
Heimerl et al. 2014 Heimerl, Florian; Steffen Lohmann;
Simon Lange; and Thomas Ertl (2014). “Word Cloud Explorer: Text
Analytics based on Word Clouds.”
47th Hawaii International Conference on System Sciences,
Jan 2014, 1833–1842. DOI: 10.1109/HICSS.2014.231
Herzog 2016 Herzog, Werner, dir. (2016). Lo and Behold: Reveries of the Connected World(2016). New
York: Magnolia Pictures. Film.
Jänicke et al. 2015 Jänicke, Stefan, Greta Franzini,
Muhammad Faisal Cheema, and Gerik Scheuermann (2015). “On Close
and Distant Reading in Digital Humanities: A Survey and Future
Challenges.”
Proceedings of the Eurographics Conference on Visualization
(EuroVis) Cagliari, Italy, 25–29 May 2015.
http://www.informatik.uni-leipzig.de/~stjaenicke/Survey.pdf
Jänicke et al. 2017 Jänicke, Stefan, Greta Franzini,
Muhammad Faisal Cheema, and Gerik Scheuermann (2017). “Visual
Text Analysis in Digital Humanities.”
Computer Graphics Forum, 36(6), 226-250.
https://doi.org/10.1111/cgf.12873.
Koolen et al. 2012 Koolen, Coorina, Alex Garnet, and
Raymond G. Siemens (2012). “Electronic Environments for Reading:
An Annotated Bibliography of Pertinent Hardware and Software.”
Scholarly and Research Communication, 3(4), 1-62.
Landow 2006 Landow, George P. (2006). Hypertext 3.0: Critical Theory and New Media in an Era of
Globalization. Baltimore, MD: The Johns Hopkins University Press.
Mangen et al. 2016 Mangen, Anne, and Adriaan van der
Weel (2016). “The evolution of reading in the age of
digitisation: an integrative framework for reading research.”
Literacy, 50(3), 116-124.
https://onlinelibrary.wiley.com/doi/abs/10.1111/lit.12086
Mangen et al. 2019 Mangen, Anne, Gérard Olivier, and
Jean-Luc Velay (2019). “Comparing comprehension of a long text
read in print book and on Kindle: Where in the text and when in the
story?”
Frontiers in psychology: cognitive science. 15 February
2019 https://doi.org/10.3389/fpsyg.2019.00038
Manovich 2011 Manovich, Lev (2011). “What is visualisation?”, Visual
Studies, 26(1), 36-49. DOI:10.1080/1472586X.2011.548488
Marshall et al. 1995 Marshall, Catherine C., and Frank
M. Shipman (1995). “Spatial hypertext: designing for
change.”
Communications of the ACM, 38(8), 88-97. August 1995
https://doi.org/10.1145/208344.208350
Mohammad 2012 Mohammad, Saif M. (2012). “From once upon a time to happily ever after: Tracking emotions in
mail and books.”
Decision Support Systems, 53(4), 730-741. DOI:
10.1016/j.dss.2012.05.030
Moulthrop 1991 Moulthrop, Stuart (1991). “You Say You Want a Revolution? Hypertext and the Laws of
Media”. Postmodern Culture, 1.3. DOI:
https://doi.org/10.1353/pmc.1991.0019
Moulthrop and Grigar 2017 Moulthrop, Stuart, and Dene
Grigar (2017). Traversals: The Use of Preservation for Early
Electronic Writing. Cambridge, MA: The MIT Press.
Murray 2012 Murray, Janet H. (2012). Inventing the Medium: Principles of Interaction Design as Cultural
Practice. Cambridge, MA: The MIT Press.
Nelson 1965 Nelson, Theodor H. (1965). “A File Structure for the Complex, the Changing, and the
Indeterminate.”
Association for Computing Machinery: Proceedings of the 20th
National Conference, 84–100.
Nelson 1995 Nelson, Theodor H. (1995). “The Heart of Connection: Hypermedia Unified by Transclusion.
”Communications of the ACM 38(8),
31–33.
Nelson 2003 Nelson, Theodor H. (2003). “Computer Lib/Dream Machines” (1974). The New Media Reader, ed. Noah Wardrip-Fruin and Nick Montfort.
Cambridge, MA: MIT Press. 303-338.
Pizzaro 2010 Pizarro, Jerónimo, ed. 2010. Fernando
Pessoa, Livro do Desasocego. Edição Crítica das Obras de
Fernando Pessoa, Vol. XII (Tomos I e II). Lisboa: Imprensa Nacional-Casa
da Moeda.
Portela 2017 Portela, Manuel (2017). “The Book of Disquiet Archive as a
Collaborative Textual Environment: From Digital Archive to Digital
Simulator.”
The Writing Platform: Digital Knowledge for Writers.
Brisbane: Queensland University of Technology. Web.
URL: https://thewritingplatform.com/2017/07/book-disquiet-archive-collaborative-textual-environment-digital-archive-digital-simulator/
Portela 2019 Portela, Manuel (2019). “The LdoD Archive as a creative
textual environment and a model of literary performativity.”
Computational Creativity Meets Digital Literary Studies,
Dagstuhl Reports, Edited by Tarek Richard Besold, Pablo Gervás, Evelyn
Gius, and Sarah Schulz, 9(4), 87–106 [p. 98].
Portela 2022 Portela, Manuel. “From
Meta-Editing to Virtual Editing: The LdoD
Archive as a Computer-Assisted Editorial Space.” Approaches to Teaching Pessoa's The Book of Disquiet.
Eds. Paulo de Medeiros and Jerónimo Pizarro. New York: Modern Language Association.
[forthcoming].
Portela and Magalhães 2020 Portela, Manuel, and Cecília
Magalhães (2020). “The Book of Disquiet Digital Archive as a
Role-Playing Experiment.”
Attention à la Marche! Mind The Gap! Thinking Electronic
Literature in a Digital Culture. Eds. Bertrand Gervais and Sophie
Marcotte. Montréal: Les Presses de l'Écureuil. 307-325.
Portela and Rito Silva 2015 Portela, Manuel, and
António Rito Silva (2015). “A model for a virtual LdoD.”
Digital Scholarship in the Humanities, 30(3), 354-370.
http://dx.doi.org/10.1093/llc/fqu004
Portela and Rito Silva 2017 Portela, Manuel, and Rito
Silva, António, eds. (2017). Arquivo LdoD: Arquivo Digital
Colaborativo do Livro do Desassossego. Coimbra: Centro de Literatura
Portuguesa da Universidade de Coimbra. URL: https://ldod.uc.pt/
Rito Silva and Portela 2015 Rito Silva, António, and
Manuel Portela (2015). “TEI4LdoD: Textual Encoding and Social
Editing in Web 2.0 Environments.” Journal of the
Text Encoding Initiative, 8. URL :
http://journals.openedition.org/jtei/1171. DOI : 10.4000/jtei.1171
Singhal 2001 Singhal, Amit (2001). “Modern Information Retrieval: A Brief Overview.”
Bulletin of the IEEE Computer Society Technical Committee on
Data Engineering 24 (4), 35–43.
Sobral 2008 Sobral Cunha, Teresa, ed. 2008. Fernando
Pessoa, Livro do Desassossego por Vicente Guedes, Bernardo
Soares. Lisboa: Relógio d’Água. [First ed. 1990-91]
Solís and Ali 2011 Solís, Carlos, and Nour Ali (2011).
“An Experience Using a Spatial Hypertext Wiki.”
HT '11: Proceedings of the 22nd ACM conference on Hypertext and
hypermedia, June 2011, 133-142. DOI: 10.1145/1995966.1995986
Theng and Thimbleby 1998 Theng, Yin Leng, and Harold
Thimbleby (1998). “Addressing Design and Usability Issues in
Hypertext and on the World Wide Web by Re-Examining the ‘Lost in
Hyperspace’ Problem.”
Journal of Universal Computer Science, 4(11),
839-855.
Theng et al. 1996 Theng, Yin Leng, Matthew Jones, Harold
Thimbleby (1996). “‘Lost in hyperspace’:
Psychological problem or bad design?”
Proceedings 1st Asia-Pacific Conference on HCI,
387-396.
Vilaplana and Pérez-Montoro 2017 Vilaplana, Jaume
Nualart, and Mario Pérez-Montoro (2017). “Diggersdiaries: Using
text analysis to support exploration and reading in a large document
collection.”
Eurographics Conference on Visualization (EuroVis), Posters
Track (2017), A. Puig Puig and T. Isenberg, Eds. 9-11. DOI:
10.2312/eurp.20171156
Viégas et al. 2009 Viégas, Fernanda B., Martin
Wattenberg, and Jonathan Feinberg (2009). “Participatory
visualization with wordle.”
IEEE Transactions on Visualization and Computer
Graphics, 15, 1137–1144. DOI: 10.1109/TVCG.2009.1
Zenith 2012 Zenith, Richard, ed. 2012. Fernando Pessoa,
Livro do Desassossego. Lisboa: Assírio & Alvim.
[First ed. 1998]