Abstract
Many “ends” of editing in the digital world may be distinguished. One may speak
of “end” as in the supersession of one model of editing (the
“intentionalist,”
“definitive-text” model) by another (the multiple texts, multiply-intentioned
views enabled by digital methods). One may speak of “end” as in aim: not only
the aim of the author or authors, but also the aims of the editor or editors. These
questions were already complicated in the print world; the advent of digital methods
has both focussed and widened the contests around these concepts. The essay reviews
some of these questions, with examples drawn from (inter alia) the utterances of the
two George Bushes, from editions with which the author is associated of Chaucer,
Dante, and of Armenian texts, from the eColi genome, and from Barack Obama's
discussion of different viewpoints on the Constitution of the United States. The
essay concludes that a huge shift is indeed underway in the editing world, towards a
more open and participatory model of editing and reading.
Texts, we have often been reminded over the last years, are social objects.
[1]
Most certainly, the practice of textual scholarship is a social activity: the concern
and product of a community. The inaugural symposium of the textual studies working group
at Texas A&M University, held on the subject of “Digital Textual Studies” at
College Station in October 2006, brought together many of the thinkers and actors in
textual scholarship in the digital age. This was an opportunity to refresh the
community, and to consider, collectively, where we are and where we are going. The title
of this essay (which was also the title of my talk to the conference) reflects something
of the collective purpose of this community, and this conference. The conference itself,
and discussions around it, spoke out loud that this is an exciting time to be a textual
scholar. Traditional boundaries are disintegrating, as new opportunities open up around
us. It is a time of great possibility for us, the fellowship of textual scholars — but
opportunity brings its own dangers. Times of change are also times of fear, as border
wars spring up around the moving boundaries of our subject. We are moving, certainly,
but to where? Do we know where we want to go and how we are going to get there? Where,
exactly, are we heading?
“Ends” implies not just end-places: it implies direction and intention, the point
aimed-for as well as the point reached. For textual scholars, as indeed for literary
scholars in general, discussion of intention has become part of a larger discourse. We
know, rather too well maybe, that once a text leaves its author’s hands, it leaves the
author’s control. Some textual editors, once upon a time, tried to reverse history by
trying to recover the author’s intentions, and so to establish the text the author
really meant. Some of us, more recently, have come to see this as a rather futile
enterprise and have concentrated on mapping the text as social object: it is a thing
made by many, with the author’s words being only one link in a long chain of
circumstances. Most of us, I guess, have placed a small bet on both: we would like our
editions to reflect the author’s words, and we would like to show all the histories of
the text, too.
[2]
This brief outline points up a major shift in editing practice and theory over the last
decades. It used to be that editors worried about only one set of intentions: the
intentions of the author. If we could recover those to our satisfaction, then we could
recover the text, we could print that, place a seal of approval on it, and feel content
that we had made the best edition we could, according to the author’s revealed
intentions.
[3] This view of editing rested on a chain of confident assertions. First,
that the author had a single intention, or at least a coherent set of intentions;
second, that we editors can recover this intention or intentions; third, that one can
apply our new knowledge usefully to the text to produce, fourth, a text which is truer
to the author’s now-revealed intention or intentions. It would be hard to find an editor
now who subscribes to this set of assertions. Further, a new set of intentions has
entered the equation. As editors, now we worry about our own intentions. Just whom are
we making this edition for, and why?
There is a further complication: texts no longer seem so simple. College Station is the
home of the George H. Bush presidential library. The single most memorable phrase
associated with George Bush, the phrase which arguably won him the 1988 election, was
his declaration “Read my lips: no new taxes.”
Millions of people did, and voted for him. But by 1990, there was a new perception:
This is the kind of text we textual scholars love. We can argue over the nature of the
utterance. Did George Bush actually say these words? Does mouthing the words in front of
millions of people, over many months, make it a text? Did he really mean it? George
Bush’s statement is a candidate for that wonderful category, of very important texts
which we all think somebody spoke, but they didn’t actually say. John Sutherland —
sometime editor of Thackeray, and therefore at least in theory a textual editor —
produced an attractive list of things people never did actually say:
- Jim Callaghan: “Crisis? What crisis?”
- Captain Kirk: “Beam me up, Scotty.”
- Sherlock Holmes: “The game's afoot!”
- Rick: “Play it again, Sam.”
- Johnny Weismuller: “Me Tarzan, you
Jane.”
- The Bible: “Spare the rod and spoil the
child.”
- Hamlet: “Alas, poor Yorick, I knew him
well.”
- George W Bush: “I know that I have never said
there is a direct link between September 11th and al-Qaida.”
- Wellington: “A damned close-run thing.”
- Nelson: “Kiss me Hardy.”
In one, and only one of these cases, according to Sutherland, did the person
credited with saying it actually say it.
[4] Later in the essay, I will tell you who Sutherland thinks it is.
One could define the business of textual scholarship as the recovery of utterance, and
the building of texts from utterance. We see now that it is not enough just to recover
what was actually said: we have to discover who said it, who heard it, what those
hearing thought they said, what the person speaking thought he or she said — and then,
repeat that exercise for every act of repeating what was, or was not, said.
Actually, I think textual scholars always knew this, but it is the business of theory to
persuade us that what we have always been doing is a new-minted discovery. And, there is
a distinct difference for us as editors now, a difference that was directly the result
of technology. Our ambitions, as editors, used to be severely circumscribed by the
printed page. Among the many things we might report, we might have space to print one,
and one only: and usually, this was the text of the utterance that we thought we had
recovered.
Now, like Texas, the wide-open plains of digital technology lie before us. We are
invited to fill this space with our editions: how should we do this? What did we do,
when we first say the endless space of gigabytes of storage? A small history lesson is
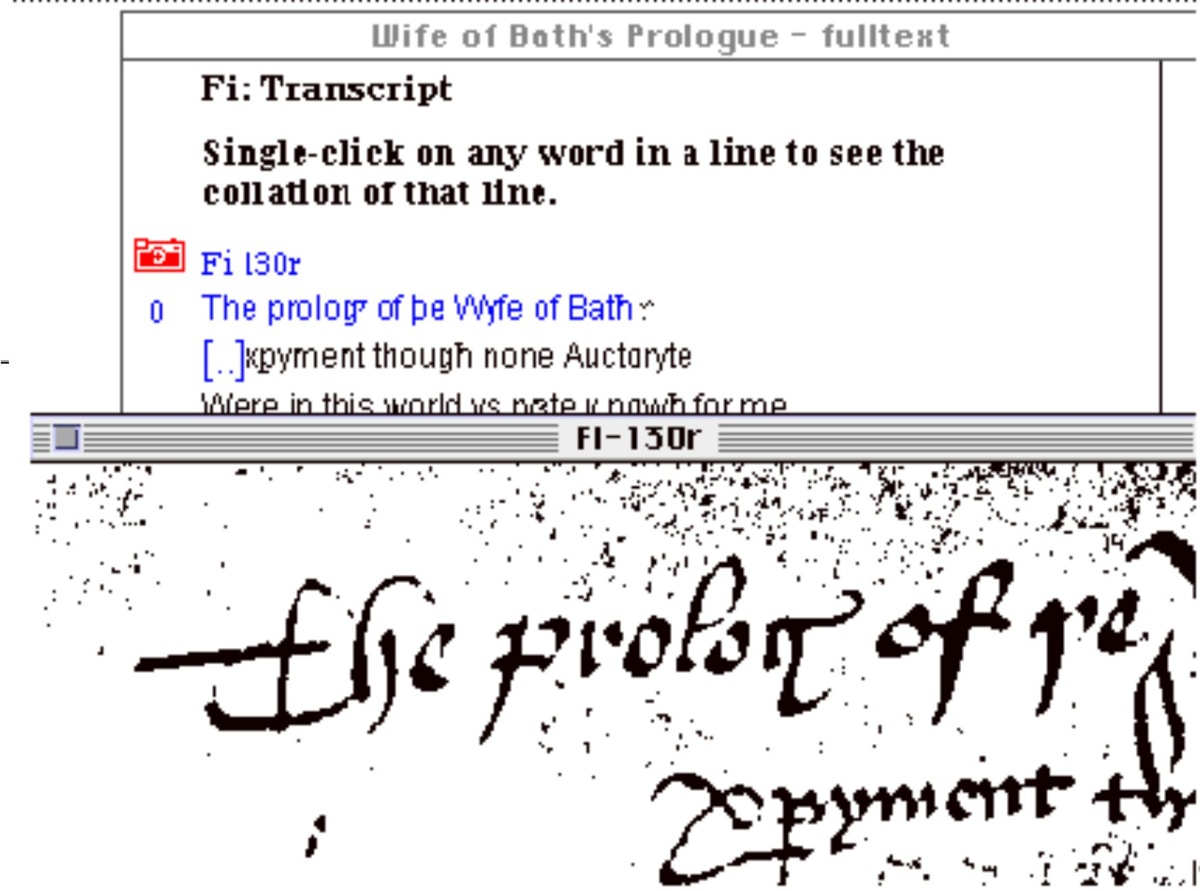
in order. Here is my first, published over ten years ago: Geoffrey Chaucer’s Wife of
Bath’s Prologue on CD-ROM, published by Cambridge University Press in 1996 [
Robinson 1996]. Rather notoriously, this gives you all the manuscripts of
the Wife of Bath’s Prologue, in transcription; in what we now see as rather poor images,
but which seemed marvellous then; and we also included a full word-by-word collation of
all the manuscripts.
When I look back at this edition, I do wonder: just what did I think I was doing? One
answer is that I believed then, as I do now, in Carolyne Macé’s wonderful dictum: “Every text deserves to be well-edited.”
Several of us heard Caroline say this in the European Society for Textual Scholarship in
Alicante in November 2004. However, she was speaking without a written text, and denies
that she ever used quite these words: the wonders of utterance, the magic of textual
scholarship. To me, a “well-edited” Canterbury Tales in the electronic medium, in
1996, meant first and foremost to make all the material available. So that is what we
did: over a thousand manuscript images; tens of thousands of words of transcription;
descriptions of each manuscript; massive spelling databases.
But we did not ourselves provide any analysis of all this material. In retrospect, our
strategy — of publishing materials without analysis — might have been a mistake. There
was much rhetoric at the time about the glories of so-called “un-editing”:
presentations of the documents which were simply that, presentations of the
documents.
[5] We were then going through one of those periods of academic
self-flagellation and guilt, along the lines of, who are we, as privileged, and usually
male, academics in comfortable western universities, to impose our views on anyone else?
(Actually, in those days we all had short-term contracts so we were not comfortable at
all.) Who are we to privilege one text over another, by “foregrounding” it in some
way? So welcome to the wonderful world of electronic archives, where all texts are
equal, where editors gracefully withdraw to leave their readers the maximum freedom to
make up their own minds about what it is they are reading. By publishing the materials
without the analysis people thought: ha! An electronic archive! Wonderful! And, as often
happens, I found myself praised for what seemed to me quite the wrong reasons.
[6]
The truth is rather different — or at least, my intentions were different. Our real
intention, which we declared as often and as loudly as we could but never, apparently,
often and loudly enough — was to use all the tools at our disposal to try to understand
the textual tradition. After we had understood the textual tradition, then we would
think about how we might edit the text, and how we might present what we had discovered.
By 1996, when we published the Wife of Bath’s Prologue, we had already moved somewhat
towards this goal. But we had a lot of pressure on us to publish that year. We were not
ready then to publish the analyses, but we were ready to publish the materials: so, that
is what we did. We then did indeed publish the analyses in print form, the next year, in
the project’s Occasional Papers series [
Robinson 1997, 69–132].
We went further than this, in the next major project publication, Elizabeth Solopova’s
edition of the General Prologue [
Robinson 2000]. We included in this a
full stemmatic analysis and commentary. With various partners, we had developed some
remarkable tools which we used to make this analysis and commentary. We also included
the tools we used to make the analyses: the variant database, and the evolutionary
biology software. We included also a variant-by-variant analysis of the key variants in
the General Prologue: altogether, many hundred pages of editorial text altogether.
Indeed, we always intended to include all this in the Wife of Bath’s Prologue: our aim
did not change between 1996 and 2000.
But something did happen between 1996 and 2000. Along the way, too, we had found
ourselves a new aim. When we made the Wife of Bath’s Prologue, our editorial intention
corresponded perfectly with Caroline Macé’s dictum: we just wanted to edit the text. We
did not think at all about who might use it, how they might use it. I suppose in this,
we are like many editors. We start editing a text because we are curious. We want to
know what is going on inside that text. How did it get made? Where did it come from? How
did it get published? What happened next? Even when we do come to try to explain to
others what we have found, we assume that anyone else who is interested in this will be
prepared to make a fairly considerable effort to understand, as we have done. So, we do
not have to try too hard to make our editions attractive or accessible.
This view corresponds to the traditional cleavage between “scholarly editions” and
what you might call “reading editions” — or, popular editions. Scholarly editions —
the full-dress performances of the Center for Editions of American Authors, or of those
published in the great Oxford and Cambridge series — were made by textual scholars for
other textual scholars. “Popular editions” are made for ordinary readers.
Many of us, around the mid ‘90s, thought that the electronic medium offered a way past
this separation of the scholarly editor from the ordinary reader. The web had just hit
and those digital spaces had got even vaster. Now, we could imagine that we could put
our edition on the web and everyone everywhere — every reader — could see what we have
done. We could cut out the middleman, the publisher, the chain of other scholars and
editors who take our work and repurpose it for different audiences, different
publications. No, we could do it all: we could take all we have learned, all the
materials we have so lovingly gathered and slaved over, and we could give it to
everyone.
In our General Editor’s preface to the 2000 General Prologue CD-ROM, Norman Blake and I
put this as follows:
[7]
One might summarize the shift in our thinking in the
last two years, underlying the differences between the two CD-ROMs, as follows: the
aim of The Wife of Bath’s Prologue CD-ROM was to help editors edit; our aim now is
also to help readers read.
So here is a new intention indeed. And following
this new intention, we asked ourselves, what can we do to reach all those readers who,
we are sure, must be out there somewhere? One way is to be useful — to include
information that might help the reader read. Another way to reach readers is to try to
make our publications attractive. That led us to develop a whole new interface for our
publications. We took the opportunity to remedy the other deficiencies we saw in the
DynaText publication system: chiefly, its inability to display a single page of
transcription at a time, or to do proper keyword in context type search reports. The
idea behind this was to make this as easy to use as possible, as transparent as
possible, and even beautiful. I don’t know how far we got towards that aim. But at the
very least, we did make something which looked nicer than the DynaText interface we had
before.
This goes some way beyond just “making material available.” To speak only of the
publications we have put out since 2000 under the Scholarly Digital Editions imprint, we
commonly present what you could call “text plus”: one or many texts linked with
many other texts, typically with links from every word in the text to many texts. In the
“single tale” publications from the Canterbury Tales project, or in Prue Shaw’s
edition of Dante’s
Monarchia, every word in every version
is linked to every word in every other version. In the
Parliament
Rolls of Medieval England every paragraph of transcription of the original
roll is linked to a matching paragraph of translation into modern English, with further
links in each parliament to introductions, appendices and images. A different approach
to “text plus” was taken by Jos Weitenberg’s Leiden Armenian Lexical Textbase.
[8] The Armenian and Greek lexica and wordlists within this distinguish some
100,000 distinct lexical forms. Every one of these lexical forms is linked to every
occurrence of any related word through the texts included in the textbase, spanning the
major period of classical Armenian down to the eighth century. In turn, every word in
these texts is linked back to its lexical form, and categorized by its part of
speech.
It has been pleasing to do this work, and pleasing to bring such editions to readers.
But I confess that in one way, I am disappointed. We thought that once we had shown that
you could make such editions like this, many people would follow. Actually, very few
people have followed. Why is this?
There are several reasons. The first reason is this: these editions are very difficult
to make. Making a real electronic scholarly edition is far, far harder than writing a
book, and takes far, far longer. Anyone who has had anything to do with electronic
editions will tell you this. Of course it does not have to be that way. You can have the
library photograph your manuscript, you can stick the photos on the web, you can make a
transcription in HTML, or Word, or something, you can write a glowing introduction, and
you can say that is an electronic edition. Certainly, that is much easier. But if we are
talking about a real digital scholarly edition, one that looks at every word in every
significant source, which transcribes every word into electronic form, which checks the
transcript over and over again, which then collates every word in every version, which
checks and alters and fine-tunes the collation over and over, which then corrects the
transcription again, then the collation again, which then tries to work out what is
going on in all those versions by looking at the collation, which then writes a
commentary explaining all this, then prepares an edited text using the conclusions from
the commentary, then starts checking how the transcripts, collations, commentaries,
editorial tools all appear...if this is what you want to do, here is what I will tell
you. Sell the family dog. Lock the door to your study and don’t come out for twenty
years.
A very few people indeed have run this course. Prue Shaw has: she started work on the
Monarchia nearly forty years ago. She made her first electronic transcripts, using an
ancient terminal in the Cambridge computer centre, twenty-five years ago. Jos Weitenberg
has: he began collecting electronic data for his Armenian in the 1970s. He still has, in
his office in Leiden, an ancient Windows computer running an antique version of Windows
with a DOS prompt, so that he can use the same programs he has been using for twenty
years now.
But if that were the only problem, that would not be too bad. After all, many academics
like working for irrationally long periods on obscure projects, on texts nobody has ever
heard of, all on their own, inserting arcane codes into strings of symbols. If making
these editions just meant working a very long time on your own, that would be fine. But
it does not. These scholars could not make these editions on their own. At every point,
they needed our help. For the Monarchia, and now the Commedia: I estimated that Prue Shaw and I have exchanged some
2000 emails over nearly twenty years of collaboration. We have spent countless hours, in
Italy, in England, in Australia, poring over the details: how do we transcribe this,
collate that, show this and that together. As to the Leiden Armenian Lexical Textbase: I
met Jos first in 1998, and once more have spent many weeks in Leiden; he has visited us,
in Leicester and Birmingham. I have not even mentioned our work with the Institute for
New Testament Research in Munster: since 1998, I have spent at least four weeks every
year, some years more, helping them work out how to move their massive work on the 5000
or so manuscripts of the Greek New Testament into the digital era.
There is a model of collaboration which I see everywhere. The model is “Scholar + Tame
Expert”:
- The scholar does all the scholarly work
- Sometimes, he or she meets with the expert
- At many points the scholar and the expert discuss what is being done; the
expert reviews it; takes samples; says what is wrong or right; passes it back to
the scholar
- At the end: the scholar passes the work over the expert, who spends much time
putting it into publishable electronic shape and finally puts it on the web
(usually)
This is how we worked; this is how I see that IATH works, and how Kings College
works, and how Michigan works, and how Brown works, and indeed every place that does the
thing called “humanities computing” works.
Twenty years ago, ten years ago, when we were still in what you might call the days of
heroic experiment, this was the way we had to do things. We did not know how to make
editions such as these, so a few experts needed to work with a few scholars to make
them. In Michael Sperberg-McQueen’s metaphor, we were the canaries sent into to test
that the air was breathable.
[9]
But we are now past this time of experiment. We now know how to make these editions. But
the model, of many scholars dependent on a very few technical experts, still holds. Now,
for we technical experts, for the few of us working at the few such technical support
centres, this is a very pleasant model. In a time of expanding funding for digital-based
research, we have done well out of this.
However, this is a broken model. In this model, there are many scholars, and few
experts. This has all sorts of consequences. It means that the only scholars who can do
this work are those with access to the experts. Generally, that means you have to be at
Virginia, or Kings. Or, you have to have a problem that really interests one of the
experts. Or, you have to have a lot of money: which generally means, you are editing one
of the “canonical” texts which everybody has heard of. If you are editing William
Gilmore Simms, don’t bother. Or, you can marry an expert, or, if the law won’t allow
that, you can form a stable long-term civil partnership with an expert. This means that
we divide scholars into the very few who are able to make such editions because they
have this access, and the very many who stand on the sidelines and watch. We should not
be surprised if a few of the very many whisper behind their hands, saying, hmm, these
digital editions, they cost so much, and really they aren’t worth making — the people
who make them aren’t Real Scholars, and so on.
We should be moving past experiment, to a point where everyone can do what, so far, only
a very few of us have been able to do. But we are trapped with a model of how humanists
work with computing tools which does not allow this. Imagine how absurd it would be, if
every time you wanted to use email, or to write a Microsoft Word document, you had to go
consult an expert. It should be possible for any scholar, with reasonable computer
skills, to make an electronic edition such as those we have made. The solution to this
is not to create more centres for humanities computing, like Kings or IATH. The solution
is not to create more experts. What most scholars need is not IATH, and not Kings, and
not more experts: they need tools and resources to let them do what they want to
do.
[10]
So: better tools. The tools for making electronic editions — and I know this, because I
have made some of them — are usable by a very few, and only then with constant
nursemaiding and attendance from their makers. I am not the only person to recognize
this. There are some impressive enterprises around, which aim to provide a new
generation of tools for scholars: the TAPOR tools now emerging from Canada; those coming
from the NINES and related enterprises in Virginia; the EPT suite which Kevin Kiernan is
putting together. In Europe, the TextGrid and Interedition partnerships are moving in
the same direction.
[11]
The aim must be, as I have put it elsewhere, that any scholar who can make a print
edition should be able to make an electronic edition. In fact, I think we can do far
better than this. Our aim should be that every one who can contribute something to an
edition should be able to do so. Suppose that a knowledgeable reader sees an error or
omission in a transcript or a commentary. He or she can correct it in his or her own
view of that transcript or commentary. Then, in Wikipedia-like fashion, the reader could
republish the corrected transcript or commentary, and others could read them.
Take the Parliament Rolls of Medieval England, for example.
There are tens of thousands of names included in this. The editors do not provide any
annotations on these. But other people could. Here is a task for years of work: to
identify and annotate all these, to allow retrieval of say, all references to the earl
of Arundel, or to the Isle of Ely, or to all documents dealing with marriage. Take the
Commedia: Shaw is not going to provide any annotation of
the many hundreds of names which appear in the edition. But others could.
This amounts to a new paradigm for scholarly editing. Here is the old paradigm:
- The edition is made by a single scholar or single scholarly group
- The editor determines what is presented and how it is presented
- The editor controls who contributes what to the edition
- Only the editor can alter any word of the edition
Here, now, is the new paradigm:
- The edition is made by the reader from whatever is available
- The reader determines what is read and how it is presented
- The reader controls the choice of materials
- Anyone can alter any word and invite others to read the altered text
Some time ago, I referred to this model as “fluid, collaborative and distributed
editions.” Michael Sperberg-McQueen calls it the “coral reef” model: every
polyp adds its bit to the whole. Peter Shillingsburg calls these “knowledge sites.”
[12] You can see
elements of this in the blog, or in the many Wikipedia-style pages which have sprouted
up everywhere.
This will not happen on its own. Just what is going to be needed, to make all this
happen?
First of all, the lifeblood of this is going to be texts made freely available to
everyone. I want to put the transcripts of Canterbury Tales manuscripts up out there on
the web, for everyone. If this all works, I am very soon going to see those transcripts
turning up all over the place, in all kinds of contexts, with all kinds of annotations,
being used for all kinds of things I did not expect. I think this is wonderful.
I have to say, not everyone feels this way. There are people who think, I transcribe a
text. It is my transcription. I want to be the only person who changes it. I want to
control who looks at it: only my friends can touch it, and even then, only after they
ask me very politely. Now, the view of the dynamic text I propose cuts right across
this. In this view, the text belongs to everyone who works on it. Further, anyone can
work on it, without having to get the permission of anyone else. There are many people
in the academic world who find the idea that the text they are working on is not their
exclusive property deeply disturbing.
I believe that people who think this way are backing themselves into an intellectual
cul-de-sac. More than that, with one important exception, any texts which come with such
restrictions are doomed. If you make it difficult for people to use your texts by
insisting that everyone needs your permission, why, people won’t use your texts. They
will find other texts, and that is the end of yours.
I spoke of an important exception. The important exception is this: high-value,
fully-published work which combines both exceptional scholarly effort with purposeful
design and publication. An example of this is the Nestle-Aland text and apparatus: there
are decades of work behind this, by the scholars in Münster, their partners, and their
publisher. This is of such high value that, indeed, people are prepared to pay for this.
I expect that some of the materials made by the Canterbury Tales Project, and from those
publications I showed earlier, will also fall into this category. When our ideal reader
of the future builds the edition they want to read, they might choose to buy one of
these, and place it at the centre of their desktop: they will annotate this, and they
will surround it with free texts from everywhere — some of which they might annotate,
extend, correct, and pass onto others, also. We don’t need to imagine that everything
will be free for everyone. Indeed, I think a healthy digital economy of editions will
have both free materials and paid-for materials, materials which are fixed and materials
which are fluid, working alongside in a way that has not been possible up to now.
We have, in fact, a remarkable example already of how collaborative electronic editions
can be made, read, used, and remade in an endless chain: in what is certainly the
largest and most productive act of collective making and reading of texts there has ever
been, and one which, in the centuries to come, is likely to transform our lives. Here is
one of the places where this reading and making has been happening:
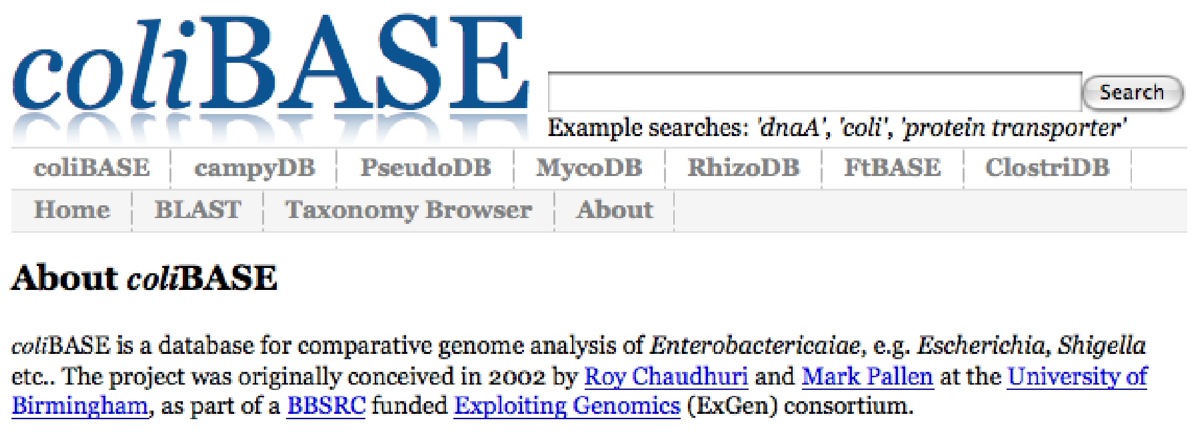
This is the ColiBase database, the genome of the E.coli bacteria at the
University of Birmingham. Here is a fragment of the text of part of the
Salmonella enteritidis bacteria (actually, region 1-20000 of
Salmonella enteritidis PT4 Contig sePT4_219c07_q1kw.).
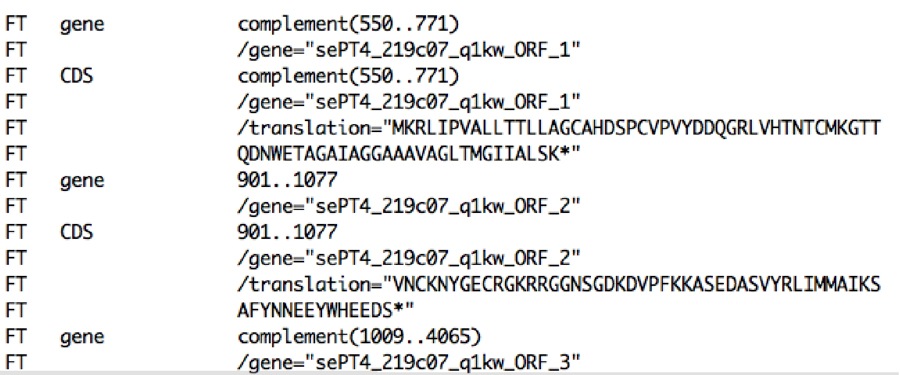
This is what is called an annotated gene:
Now, here below is the gene itself, with each three-letter sequence spelling out a word:
one of the twenty amino acids, or a control code:
Over the last decades, evolutionary biologists have created an astonishing
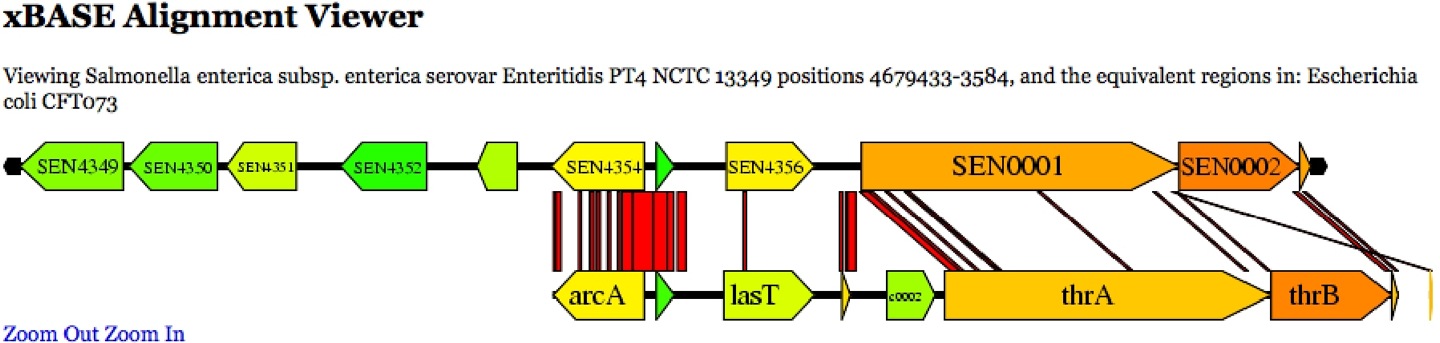
array of tools to read these texts. For example, you can compare the texts of genes.
Here is a comparison of part of this gene,
Salmonella
enteritidis PT4 with the related region from region from
Escherichia coli:
These, of course, are not just academic exercises. On the basis of diagrams such as
these, scientists calculate exactly what parts of the genome are responsible for which
diseases and develop medicines to attack those diseases. This remarkable work has only
been possible because of the agreement that the heart of this information should be
freely available to all researchers — an agreement which has not at all excluded
commercial agents from using this data, since tools and other data are not free. I think
this is a good model for how we can work together. For us, digital images of original
sources and transcripts are the raw genome data. Make those available, free, for all to
use, change, annotate, supplement, compare, discuss, and all things will be
possible.
Finally, I want to return to my list of things which people did or did not say,
according to Sutherland. In the year 2006 when I gave this talk in Texas, during the
presidency of George W. Bush, it was assumed that it must be the Bush quotation which,
according to Sutherland, is the one real quotation. Sutherland says, “You can hear it, live, on Neil Young's ‘Let's Impeach
the President,’ along with the original quotation in which Bush did assert
there was a link.” This sounds convincing. But actually, so far as I can
discover from downloading the Neil Young album, it appears that, at the very least,
Sutherland was listening to a different album from any I can find: there is lots of Neil
Young on the album, but no George Bush. Indeed, while Young makes many accusations about
Bush, he does not make this particular accusation. And furthermore, so far as I can
discover, it appears that Bush never did say what Sutherland says he said. The nearest I
can discover is this statement, by Bush in a press conference on March 20, 2006:
I don't think we ever said — at least I know I didn't say
that there was a direct connection between September the 11th and Saddam
Hussein.
And in fact, so far as I can discover, Bush is telling the truth: he
never did say there was such a direct connection. Indeed, on several occasions he was
invited by the press to make this direct connection, and each time he refused. Of
course, he and others did say many other things about Iraq and Al-qaida, but this one
thing, at least, he did not say. You could conclude several things from this. You could
conclude that John Sutherland is rather careless with the facts. You could conclude too
that Bush is not as stupid as his critics think — and maybe, that his critics are not as
clever as they think they are. But here is where the internet is at its best: in a few
moments, one can carry out the classic tasks of textual scholarship on this particular
utterance and text, or rather non-utterance and non-text, and establish (as apparently
Sutherland did not) that Bush did not say what so many of us thought he did.
In fact, the story does not end here. In the last paragraphs, I presume that you, the
reader, think that what Sutherland alleged is, Bush said that there was a direct
connection between September 11th and Saddam Hussein. Now, turn back a few pages and see
what Sutherland actually declares that Bush said (or, go to the
Guardian story published on 3 October 2006, available online at
http://www.guardian.co.uk/g2/story/0,,1886387,00.html).
What Sutherland actually has Bush say is not
“I have never said there was a direct link between
September 11 and Saddam Hussein” but “I have
never said there is a direct link between September 11th and al-Qaida.” Now,
this is a total nonsense. It is such a total nonsense that when I read this, I presumed
that the end of the quotation was “Saddam
Hussein” not “al-Qaida.” All who heard
the lecture in Texas thought the same, and indeed Sutherland seems to have think too
that he wrote “Saddam Hussein” not “al-Qaida.” Internally, we edit what we read so that
it conforms with what we think we know. We all think we know that Bush said, many times,
that there was a link between 9/11 and Saddam Hussein, so as soon as we see a quotation
from George Bush beginning “I have never said there was
a direct link between September 11 and...” we automatically the last words as
“Saddam Hussein” — and fail to see that the
text actually says something quite different (indeed, it seems that the author himself
failed to spot this). It is particularly ironic as the whole of Sutherland’s article is
about how we prefer misquotation to what people actually said — and yet Sutherland is
guilty of misquotation in the central example of his whole article.
One may ask, does this matter? Consider, again, the analogy of texts and DNA sequences I
raised earlier. Among the billions of letters of DNA sequences, only a fraction — as
little as 2% in the human genome — actually has a known function, in that it encodes
proteins of clear value to their host genome. The rest is predominantly “junk DNA”:
changes in this have no effect on the organism. As I write this, America is in the midst
of the most hotly-contested presidential campaign in decades. The country is awash with
words: from the candidates themselves, endlessly repeated, subtly or not so subtly
altered as they are repeated; from commentators, across all the media, through into the
street, the home, the workplace. Most of these words will be the equivalent of “junk
DNA”: they will float across the airwaves, through our minds and speech, to
nothing. But some will have a huge impact. A single catchphrase can win the election: we
have already seen how “Read my lips...” helped
George H. Bush in 1988; in 1992 it was “It’s the
economy, stupid.” A single error, a single casual phrase, can lose the
election; candidates and their staffs live in fear of waking up to yesterday’s gaffe on
the front pages of today’s papers. It is the human equivalent of a single rogue mutation
bringing on a catastrophic illness. Sometimes, we textual critics ask ourselves, does
our work matter? Most of the time, the many words we broker are like junk DNA: changes
in them have no effect. But a few words might, just might, have an effect out of all
proportion.
This brings us in a circle, back to the ends of editing: conceived not as an end-point,
but as an aim. American presidential politics has been a tune playing throughout this
essay, and it is apposite that we should find illumination of our aims, as textual
editors, in an argument advanced by one of the candidates for the 2008 election, Barack
Obama. In his book
The Audacity of Hope, Obama considers
different views of the U.S. Constitution. Is it to be understood as
“constructionists” (broadly, conservative Republicans) see it, as a fixed set of
rules for governing a state, so that we can surely determine modern arguments by
recognizing the original intentions of the framers, as enshrined in the Constitution? If
so, the Constitution can tell us
what to think. Or is it to be understood
as “relativists” (broadly, liberal Democrats) see it, as a set of documents
themselves the result of circumstance, which we must interpret in the light of our own
knowledge and circumstances? If so, the Constitution can, at best, tell us
how to think. Here is the same fault line as that which crosses textual
scholarship, between editors who strive to uncover original intention towards shaping a
fixed text and editors who seek to show the multiple contingencies bearing on text as
process. Obama’s position is that he wants to be neither a strict constructionist nor a
free relativist. Instead, he proposes the following:
The answer I settle on...requires a shift of metaphors, one that
sees our democracy not as a house to be built, but as a conversation to be had.
...What the framework of our Constitution can do is organize the way by which we
argue about our future. All of its elaborate machinery — its separation of powers and
checks and balances and federalist principles and Bill of Rights — are designed to
force us into a conversation...[13]
This seems an excellent description of what textual scholarship does. We engage
in a conversation about the text. It is not just any conversation: we recognize certain
rules of fidelity to evidence, of respect for opposition views, and (especially) a sense
that the exact words and the circumstances of their saying matter. This requires that we
do not carelessly distort the texts under our care, or ignore what they say in favour of
what we would like them to say. Being a good textual editor is not so different from
being a good citizen: one ought to listen, ought to try to understand what is actually
being said, then ought to try to help others understand too.
In the opening paragraphs of his
From Gutenberg to Google,
Peter Shillingsburg wonders at the endurance and beauty of Gutenberg’s 42 line bible,
and asks, in 500 years, would anyone stand to look at a museum display of the first
electronic book and would the words “endurance” and “beauty” come to mind? I
think the digital humanities, and what we can do with them, offer something far better
than a single book, locked in a single library. They offer us the chance to become more
skilful, better-informed readers. They offer all of us the chance to make up our own
minds about utterance and text, and not just accept what anyone tells us. After all,
that was always the best function of books — and with the new electronic books of the
future, we can do this better than print books ever could.
[14]